
Table of Contents
728x90

이 이미지에서는 다양한 최적화 알고리즘에 대해 설명하고 있습니다. 각 알고리즘은 기계 학습 모델의 손실 함수를 최소화하기 위해 사용되며, 서로 다른 방식으로 학습률과 스텝 크기를 조정합니다. 이를 이해하기 쉽게 하나씩 설명해드리겠습니다.
1. GD (Gradient Descent)
- 설명: 모든 데이터를 사용하여 손실 함수의 기울기를 계산하고, 그 방향으로 이동하여 최소값을 찾습니다.
- 특징: 모든 데이터를 사용하기 때문에 계산 비용이 큽니다.
- 예시:
import numpy as np
#X: 독립 변수(특성) 데이터. 여기서는 𝑚×𝑛 형태의 2차원 배열입니다.
#y: 종속 변수(목표) 데이터. 길이가 𝑚인 1차원 배열입니다.
#learning_rate: 학습률. 각 반복에서 계수를 얼마나 크게 업데이트할지를 결정합니다.
#학습률을 곱함으로써 파라미터가 한 번에 얼마나 크게 변화할지를 조절합니다.
#학습률이 너무 크면, 파라미터가 최적값을 넘어서서 진동하거나 발산할 수 있습니다.
#반대로 학습률이 너무 작으면, 파라미터가 천천히 변해 수렴하는 데 시간이 오래 걸립니다.
#iterations: 경사 하강법을 수행할 반복 횟수
def gradient_descent(X, y, learning_rate=0.01, iterations=1000):
#데이터 포인트의 수를 저장합니다.
m = X.shape[0] #X.shape=>(3,2), X.shape[0]=>3
#회귀 계수를 초기화합니다. 처음에는 모든 계수가 0입니다.
theta = np.zeros(X.shape[1])#X.shape[0]=>2, theta=>array([0., 0.])
for _ in range(iterations):
#기울기(gradient)를 계산합니다. 이는 현재 회귀 계수에 대한 손실 함수의 기울기입니다.
#X.dot(theta): 현재 회귀 계수를 사용하여 예측값을 계산합니다.
#X.dot(theta) - y: 예측값과 실제값 간의 차이를 계산합니다.
#X.T.dot(...): 특성별로 차이를 누적하여 계산합니다.
#(1/m) * ...: 평균을 계산하여 기울기를 얻습니다.
gradient = (1/m) * X.T.dot(X.dot(theta) - y)#array([-17., -23.]),array([-13.66333333, -18.5 ])
#기울기에 학습률을 곱한 값을 빼서 회귀 계수를 업데이트합니다.
theta -= learning_rate * gradient#array([0.17, 0.23]),array([0.30663333, 0.415 ])
return theta #최종 회귀 계수를 반환합니다.
# 데이터 예시
X = np.array([[1, 2], [2, 3], [4, 5]])
y = np.array([3, 6, 9])
# 경사 하강법 실행
theta = gradient_descent(X, y)
print(theta) #[0.62787988 1.35221456]2. SGD (Stochastic Gradient Descent)
- 설명: 전체 데이터가 아닌 무작위로 선택된 일부 데이터를 사용하여 기울기를 계산합니다.
- 특징: 계산 비용이 줄어들고, 더 빠르게 수렴할 수 있지만 노이즈가 발생할 수 있습니다.
- 예시
def stochastic_gradient_descent(X, y, learning_rate=0.01, iterations=1000):
m = X.shape[0]
theta = np.zeros(X.shape[1])
for _ in range(iterations):
for i in range(m):
#0부터 𝑚−1까지의 정수 중에서 무작위로 하나를 선택합니다.
random_index = np.random.randint(m)
#무작위로 선택된 하나의 데이터 포인트를 선택합니다.
X_i = X[random_index:random_index+1]
#무작위로 선택된 데이터 포인트의 실제 값을 선택합니다.
y_i = y[random_index:random_index+1]
gradient = X_i.T.dot(X_i.dot(theta) - y_i)
theta -= learning_rate * gradient
return theta
# 경사 하강법 실행
theta = stochastic_gradient_descent(X, y)
print(theta)3. Momentum
- 설명: 이전 스텝의 이동 방향을 고려하여 현재 방향을 결정합니다.
- 특징: 이동 속도를 증가시키고, 진동을 줄여 더 빠르게 수렴할 수 있습니다.
- 예시:
#모멘텀 계수. 이전 속도의 영향을 얼마나 받을지를 결정합니다.
def momentum_gradient_descent(X, y, learning_rate=0.01, iterations=1000, momentum=0.9):
m = X.shape[0]
theta = np.zeros(X.shape[1])
#기존의 경사 하강법에 속도(velocity) 개념을 추가하여, 경사 하강이 더 빠르게 수렴하도록 도와줍니다.
velocity = np.zeros(X.shape[1])
for _ in range(iterations):
gradient = (1/m) * X.T.dot(X.dot(theta) - y)
#모멘텀을 사용하여 속도(velocity)를 업데이트합니다.
#momentum * velocity: 이전 속도의 영향을 반영합니다.
#- learning_rate * gradient: 현재 기울기에 학습률을 곱한 값을 빼서 새로운 속도를 계산합니다.
velocity = momentum * velocity - learning_rate * gradient
theta += velocity
return theta
# 경사 하강법 실행
#모멘텀을 사용함으로써 이전 스텝의 속도를 고려하여 현재 스텝의 이동 방향을 조정합니다.
#이를 통해 경사 하강법이 더 빠르고 안정적으로 수렴할 수 있습니다.
#최종적으로 학습된 회귀 계수는 theta에 저장됩니다.
theta = momentum_gradient_descent(X, y)
print(theta)
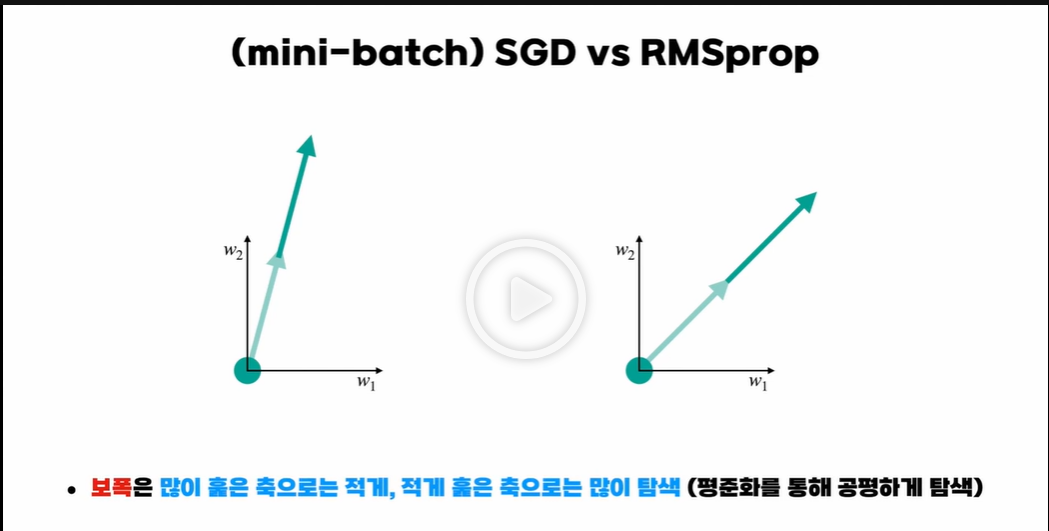
4. NAG (Nesterov Accelerated Gradient)
- 설명: 일반적인 관성 방식보다 조금 더 나아가, 미리 예상한 위치에서 기울기를 계산하여 스텝을 조정합니다.
- 특징: 더 빠르고 안정적인 수렴을 도와줍니다.
def nag_gradient_descent(X, y, learning_rate=0.01, iterations=1000, momentum=0.9):
m = X.shape[0]
theta = np.zeros(X.shape[1])
velocity = np.zeros(X.shape[1])
for _ in range(iterations):
#현재의 회귀 계수에 모멘텀을 적용하여 임시 회귀 계수(temp_theta)를 계산합니다.
temp_theta = theta + momentum * velocity
gradient = (1/m) * X.T.dot(X.dot(temp_theta) - y)
velocity = momentum * velocity - learning_rate * gradient
theta += velocity
return theta
# 경사 하강법 실행
theta = nag_gradient_descent(X, y)
print(theta)5. Adagrad
- 설명: 각 변수에 대해 학습률을 개별적으로 조정하여, 자주 등장하는 변수의 학습률을 감소시키고, 드물게 등장하는 변수의 학습률을 증가시킵니다.
- 특징: 학습률이 점점 줄어들어 결국에는 학습이 멈출 수 있습니다.
- 예시:
def adagrad(X, y, learning_rate=0.01, iterations=1000, epsilon=1e-8):
m = X.shape[0]
theta = np.zeros(X.shape[1])
gradient_sum_squares = np.zeros(X.shape[1])
for _ in range(iterations):
gradient = (1/m) * X.T.dot(X.dot(theta) - y)
gradient_sum_squares += gradient ** 2
adjusted_gradient = gradient / (np.sqrt(gradient_sum_squares) + epsilon)
theta -= learning_rate * adjusted_gradient
return theta
# 경사 하강법 실행
theta = adagrad(X, y)
print(theta)6. AdaDelta
- 설명: Adagrad의 단점을 해결하기 위해, 학습률이 너무 작아지는 것을 방지합니다.
- 특징: 최근 기울기의 크기만을 고려하여 학습률을 조정합니다.
7. RMSProp
- 설명: Adagrad와 유사하게 학습률을 조정하되, 최근의 기울기를 기반으로 조정합니다.
- 특징: 학습률이 너무 작아지는 문제를 해결합니다.
- 예시:
def rmsprop(X, y, learning_rate=0.01, iterations=1000, beta=0.9, epsilon=1e-8):
m = X.shape[0]
theta = np.zeros(X.shape[1])
gradient_sum_squares = np.zeros(X.shape[1])
for _ in range(iterations):
gradient = (1/m) * X.T.dot(X.dot(theta) - y)
gradient_sum_squares = beta * gradient_sum_squares + (1 - beta) * gradient ** 2
adjusted_gradient = gradient / (np.sqrt(gradient_sum_squares) + epsilon)
theta -= learning_rate * adjusted_gradient
return theta
# 경사 하강법 실행
theta = rmsprop(X, y)
print(theta)8. Adam (Adaptive Moment Estimation)
- 설명: RMSProp과 Momentum을 결합한 방법으로, 학습률을 적절하게 조정하면서도 이동 방향을 고려합니다.
- 특징: 빠르고 안정적인 수렴을 돕습니다.
- 예시:
def adam(X, y, learning_rate=0.01, iterations=1000, beta1=0.9, beta2=0.999, epsilon=1e-8):
m = X.shape[0]
theta = np.zeros(X.shape[1])
m_t = np.zeros(X.shape[1])
v_t = np.zeros(X.shape[1])
for t in range(1, iterations + 1):
gradient = (1/m) * X.T.dot(X.dot(theta) - y)
m_t = beta1 * m_t + (1 - beta1) * gradient
v_t = beta2 * v_t + (1 - beta2) * gradient ** 2
m_t_hat = m_t / (1 - beta1 ** t)
v_t_hat = v_t / (1 - beta2 ** t)
theta -= learning_rate * m_t_hat / (np.sqrt(v_t_hat) + epsilon)
return theta
# 경사 하강법 실행
theta = adam(X, y)
print(theta)
입실론은 pytorch에서 10의 -12승으로 잡아주고 있음. 왜냐면 분모가 0에 가깝게 작아지면 발산, 갑자기 튈 수 있기 때문에 입실론보다는 작아지지 않도록 함. 모든게 element-wise라서 각각에 대한 편미분만 보면 됨.
*element-wise: 같은 크기를 가진 두 개의 벡터나 행렬은 덧셈과 뺄셈을 할 수 있다. 두 벡터와 행렬에서 같은 위치에 있는 원소끼리 덧셈과 뺄셈을 하면 된다. 이러한 연산을 요소별(element-wise) 연산이라고 한다.
9. Nadam
- 설명: Adam에 NAG(Nesterov Accelerated Gradient)를 결합한 방법입니다.
- 특징: Adam의 장점과 NAG의 장점을 모두 활용하여 더 나은 성능을 제공합니다.
요약
이 이미지에서 설명된 최적화 알고리즘들은 기계 학습 모델의 학습 속도와 안정성을 향상시키기 위해 고안된 다양한 방법들입니다. 각 알고리즘은 학습률과 스텝 크기를 조정하는 방법에 따라 다른 특징을 가지며, 특정 문제에 더 적합한 방법을 선택하여 사용할 수 있습니다.
- GD: 전체 데이터를 사용, 정확하지만 계산 비용이 큼.
- SGD: 일부 데이터를 사용, 빠르지만 노이즈가 있음.
- Momentum, NAG: 이동 방향을 고려, 빠르고 안정적.
- Adagrad, AdaDelta, RMSProp: 학습률을 조정, 학습 속도 조절.
- Adam, Nadam: 다양한 기법을 결합, 빠르고 효과적.
이러한 최적화 알고리즘들을 통해 모델의 학습 성능을 최적화할 수 있습니다.
'ML' 카테고리의 다른 글
| 회귀(Regression)와 분류(Classification) (0) | 2024.05.28 |
|---|---|
| 스케일링 (Scaling) (0) | 2024.05.28 |
| Feature Selection (0) | 2024.05.28 |
| 모델 평가 방법 (0) | 2024.05.28 |
| 베타𝛽계수 추정, 손실함수lossfunction, 편미분partial derivative, 폐쇄형 해Closed Form Solution (0) | 2024.05.28 |
250x250
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 손실함수
- 해시
- LIST
- recursion #재귀 #자료구조 # 알고리즘
- Lora
- nlp
- Github
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- 파이썬
- English
- 티스토리챌린지
- speaking
- 오블완
- classification
- Python
- RAG
- git
- LLM
- Transformer
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- Hugging Face
- Numpy
- cnn
- 리스트
- 코딩테스트
- Array
- PEFT
- t5
- clustering
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
글 보관함