
Table of Contents
Understanding Causal LLM’s, Masked LLM’s, and Seq2Seq: A Guide to Language Model Training Approaches
꼬꼬마코더 2024. 8. 30. 15:34Understanding Causal LLM’s, Masked LLM’s, and Seq2Seq: A Guide to Language Model Training…
In the world of natural language processing (NLP), choosing the right training approach is crucial for the success of your language model…
medium.com
Causal Language Modeling (CLM)
- CLM은 자동 회귀 방식으로, 모델이 이전 토큰을 바탕으로 다음 토큰을 예측하도록 훈련됩니다. CLM은 GPT-2 및 GPT-3와 같은 모델에서 사용되며, 텍스트 생성 및 요약 작업에 적합합니다. 하지만 CLM 모델은 일방향 컨텍스트만을 고려하기 때문에, 생성 시 미래의 컨텍스트를 고려하지 못합니다. 미래의 컨텍스트를 고려하지 못한다는 것은, 언어 모델이 텍스트를 생성하거나 처리할 때, 현재 위치보다 뒤에 오는 단어들(미래의 텍스트)의 정보를 사용하지 못한다는 의미입니다. 미래의 컨텍스트를 고려하는 모델은 특히 번역, 요약 등의 작업에서 강력합니다. 이러한 작업에서 문장의 전체적인 의미를 이해하는 것이 중요하기 때문에, 문장 전체의 맥락을 파악하는 것이 성능을 높이는 데 도움이 됩니다. 반면, CLM과 같이 단방향 컨텍스트만을 사용하는 모델은 생성된 텍스트의 일관성은 유지할 수 있지만, 전체 문맥을 파악하는 데는 한계가 있을 수 있습니다.
- ChatGPT의 모델 아키텍처:
- ChatGPT와 같은 모델은 주로 GPT 시리즈와 같은 Transformer 기반의 모델을 사용합니다. 이 모델들은 자동 회귀 방식으로 텍스트를 생성하며, 주로 다음과 같은 특성을 가집니다:
- Causal Language Modeling (CLM): 이전의 텍스트만을 고려하여 다음 토큰을 예측합니다. 이 방식은 연속적인 텍스트 생성에 적합하며 대화 생성에서 매우 유용합니다.
- Transformer Architecture: Transformer는 딥러닝 모델 중 하나로, 순환 신경망이나 합성곱 신경망과 달리 attention 메커니즘을 사용하여 모든 입력 토큰 사이의 관계를 효과적으로 학습합니다. 이는 모델이 맥락을 더 잘 이해하도록 돕습니다.
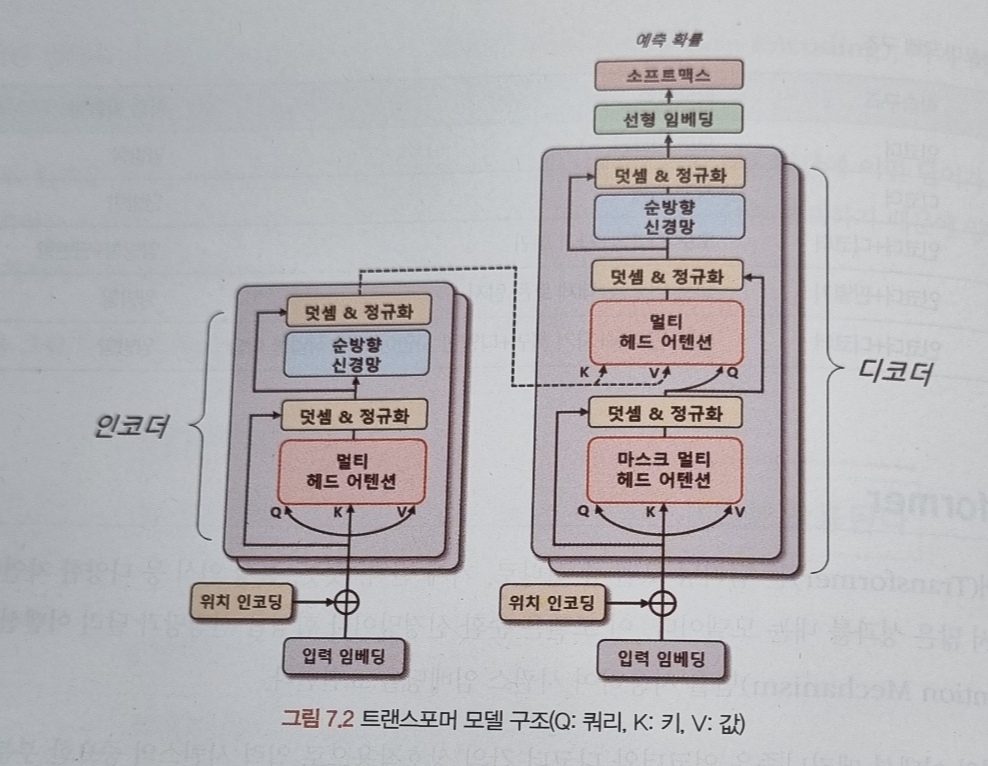
- 트랜스포머의 인코더와 디코더는 두 부분으로 구성돼 있으며, 각각 N개의 트랜스포머 블록으로 구성됩니다. 이 블록은 멀티 헤드 어텐션(Multi-Head Attention)과 순방향 신경망으로 이뤄져 있습니다. 멀티 헤드 어텐션은 입력 시퀀스에서 쿼리, 키, 값 벡터를 정의해 입력 시퀀스들의 관계를 셀프 어텐션(Self-Attention)하는 벡터 표현 방법입니다. 이 과정에서 쿼리와 각 키의 유사도를 계산하고, 해당 유사도를 가중치로 사용하여 값 벡터를 합산합니다. 이렇게 계산된 어텐션 행렬은 입력 시퀀스 각 단어의 임베딩 벡터를 데체합니다. 결국 입력 시퀀스의 단어 사이의 상호작용을 고려해 임베딩 벡터를 갱신합니다.
- 트랜스포머에서는 입력 시퀀스 데이터를 소스와 타깃 데이터로 나눠 처리합니다. 소스 시퀀스 데이터를 위치 인코딩(Positional Encoding)된 입력 임베딩으로 표현해 트렌스포머 블록의 출력 벡터를 생성합니다. 이 출력 벡터는 입력 시퀀스 데이터의 관계를 잘 표현할 수 있게 구성됩니다.
- 디코더도 인코더와 유사하게 트랜스포머 블록으로 구성되어 있지만, 마스크 멀티 헤드 어텐션(Masked Multi-Head Attention)을 사용해 타깃 시퀀스 데이터를 순차적으로 생성시킵니다. 이때 디코더 입력 시퀀스들의 관계를 고도화하기 위해 인코더의 출력 벡터 정보를 참조합니다.
Masked Language Modeling (MLM)
- MLM은 BERT와 같은 모델에서 사용되는 훈련 방법으로, 입력 시퀀스의 일부 토큰을 마스킹하고 모델이 주변 컨텍스트를 바탕으로 마스킹된 토큰을 예측하도록 합니다. MLM은 양방향 컨텍스트의 장점을 가지고 있어, 텍스트 분류, 감성 분석, 명명된 개체 인식과 같은 작업에 유용합니다.
- MLM의 작동 원리
- 텍스트 처리: 입력 텍스트에서 무작위로 특정 비율의 토큰(예: 15%)을 선택하고, 이 토큰을 "[MASK]" 토큰으로 대체합니다.
- 양방향 학습: 모델은 남은 텍스트의 맥락을 양방향(왼쪽과 오른쪽 모두)으로 고려하여 마스크된 토큰의 원래 값을 예측합니다.
- 손실 계산 및 역전파: 모델이 마스크된 위치에서 실제 토큰을 정확하게 예측하도록 손실 함수를 최적화합니다.
- 양방향 컨텍스트 이해: MLM은 문장의 전체 맥락을 고려하여 학습하기 때문에, 단어가 문장에서 어떻게 사용되는지에 대한 깊은 이해를 가능하게 합니다. 이는 특히 텍스트 분류, 감성 분석, 명명된 개체 인식(NER)과 같은 NLP 작업에서 유리합니다.
- 피처 추출기로서의 우수성: BERT와 같은 MLM 모델은 다양한 다운스트림 NLP 작업에 유용한 강력한 피처를 추출할 수 있습니다. 이 모델들은 종종 다른 특정 작업에 대한 파인 튜닝 기반으로 사용됩니다.
- 일반화 능력: MLM 방식으로 학습된 모델은 언어의 복잡성과 뉘앙스를 잘 포착하여, 새로운 데이터나 도메인에도 강한 일반화 성능을 보입니다.
- 문장 또는 문서 분류: 제품 리뷰의 감성을 분석하거나, 이메일을 긴급성에 따라 분류하는 작업에서 사용됩니다.
- 질문 응답 시스템: 특정 질문에 대한 답변을 문서 내에서 찾아내는 데 사용됩니다.
- 명명된 개체 인식: 텍스트에서 사람 이름, 기관명, 위치 등을 식별하는 데 사용됩니다.
Sequence-to-Sequence (Seq2Seq)
- Seq2Seq 모델은 인코더-디코더 구조로 구성되며, 인코더는 입력 시퀀스를 처리하고 디코더는 출력 시퀀스를 생성합니다. 이 접근법은 기계 번역, 요약, 질문 응답과 같은 작업에 흔히 사용됩니다. Seq2Seq 모델은 입력-출력 변환을 포함하는 더 복잡한 작업을 처리할 수 있어 다양한 NLP 작업에 유연하게 사용될 수 있습니다. T5나 BART와 같은 모델에서 볼 수 있는 방식입니다. 여기 몇 가지 구체적인 사용 예를 살펴보겠습니다:
- 1. 기계 번역
- 용도: 서로 다른 두 언어 간의 문장을 번역합니다.
- 작동 방식: 인코더가 입력 문장을 소스 언어로 받아 내부적인 컨텍스트 벡터로 변환하고, 디코더가 이 벡터를 사용하여 타겟 언어로 문장을 생성합니다.
- 예시: 영어 문장 "How are you?"를 스페인어로 "¿Cómo estás?"로 번역합니다.
- 용도: 긴 텍스트를 짧고 핵심적인 내용만 포함하는 요약문으로 변환합니다.
- 작동 방식: 인코더가 전체 문서를 읽어 내부 표현을 생성하고, 디코더는 이를 바탕으로 핵심적인 정보만을 포함하는 짧은 요약문을 생성합니다.
- 예시: 긴 뉴스 기사를 몇 문장으로 요약하여 주요 사실만 전달합니다.
- 용도: 주어진 질문에 대한 답을 생성합니다.
- 작동 방식: 인코더가 질문을 해석하여 컨텍스트를 이해하고, 디코더가 이 컨텍스트를 기반으로 적절한 답변을 생성합니다.
- 예시: "What is the capital of France?"라는 질문에 "Paris"라고 답합니다.
- 용도: 이미지나 비디오에 대한 설명적인 텍스트를 생성합니다.
- 작동 방식: 인코더가 이미지나 비디오의 특징을 분석하여 내부적인 표현을 생성하고, 디코더는 이를 사용하여 콘텐츠를 설명하는 캡션을 생성합니다.
- 예시: 풍경 사진을 보고 "A beautiful sunset over the mountains"와 같은 캡션을 생성합니다.
- 용도: 사용자의 입력에 따라 적절한 대화 응답을 생성합니다.
- 작동 방식: 인코더가 사용자의 질문이나 명령을 해석하고, 디코더가 이를 바탕으로 대화를 이어가는 적절한 응답을 생성합니다.
- 예시: 사용자가 "I'm feeling sad today."라고 말하면, 시스템이 "I'm sorry to hear that. Want to talk about it?"라고 응답할 수 있습니다.
주요 차이점
- CLM은 주로 텍스트 생성에 초점을 맞추고 있으며, 다음 토큰을 예측하는 것에 중점을 둡니다. 이는 텍스트 생성 작업에 적합합니다.
- MLM은 마스킹된 토큰을 예측하는 데 중점을 두며, 이를 통해 양방향 컨텍스트 이해를 강화합니다. 이는 텍스트 분류나 명명된 개체 인식과 같은 작업에 적합합니다.
- Seq2Seq는 입력에 기반한 출력 시퀀스를 생성하는 데 중점을 두고 있으며, 번역이나 요약과 같은 작업에 적합합니다.
각 모델링 기법을 이해하고, NLP 작업에 가장 적합한 훈련 접근법을 선택하는 것은 모델 성능을 최적화하고 향상된 결과를 얻는 데 중요합니다.

In the world of natural language processing (NLP), choosing the right training approach is crucial for the success of your language model. In this article, we’ll delve into the differences between Causal Language Modeling (CLM), Masked Language Modeling (MLM), and Sequence-to-Sequence (Seq2Seq) approaches, discussing their importance, and exploring best practices for using them.
Why it’s important to understand CLM, MLM, and Seq2Seq
Understanding these training methods allows you to select the most appropriate approach for your specific NLP task, ultimately enhancing your model’s performance. Each method has its unique strengths and weaknesses and is suited to different types of problems. By understanding the fundamentals of each approach, you can optimize your model’s training and fine-tuning, leading to better outcomes.
Causal Language Modeling (CLM)
CLM is an autoregressive method where the model is trained to predict the next token in a sequence given the previous tokens. CLM is used in models like GPT-2 and GPT-3 and is well-suited for tasks such as text generation and summarization. However, CLM models have unidirectional context, meaning they only consider the past and not the future context when generating predictions.
Masked Language Modeling (MLM)
MLM is a training method used in models like BERT, where some tokens in the input sequence are masked, and the model learns to predict the masked tokens based on the surrounding context. MLM has the advantage of bidirectional context, allowing the model to consider both past and future tokens when making predictions. This approach is especially useful for tasks like text classification, sentiment analysis, and named entity recognition.
Sequence-to-Sequence (Seq2Seq)
Seq2Seq models consist of an encoder-decoder architecture, where the encoder processes the input sequence and the decoder generates the output sequence. This approach is commonly used in tasks like machine translation, summarization, and question-answering. Seq2Seq models can handle more complex tasks that involve input-output transformations, making them versatile for a wide range of NLP tasks.
Key Differences in CLM, MLM, Seq2Seq
key differences in the implementation, architecture, and output models for causal language modeling (CLM), masked language modeling (MLM), and sequence-to-sequence (seq2seq) modeling.
Causal Language Modeling (CLM):
- Implementation: In CLM, the model is trained to predict the next token in the sequence, given the previous tokens. During training, the input tokens are fed into the model, and the model predicts the probability distribution of the next token. The loss is calculated based on the model’s predictions and the actual target tokens, which are just the input tokens shifted by one position.
- Architecture: CLM is typically used with autoregressive models like GPT. These models use a unidirectional (left-to-right) Transformer architecture, where each token can only attend to the tokens that come before it. This prevents the model from “cheating” by attending to the target tokens during training.
- Output Model: A fine-tuned CLM model can generate coherent text by predicting one token at a time, making it suitable for text generation tasks. However, it may not be as effective at capturing bidirectional context compared to MLM models.
Masked Language Modeling (MLM):
- Implementation: In MLM, the model is trained to predict masked tokens within the input sequence. During preprocessing, a certain percentage of tokens are randomly masked, and the model is trained to predict the original tokens at those masked positions. The loss is calculated based on the model’s predictions and the actual target tokens (the original tokens that were masked).
- Architecture: MLM is used with models like BERT, which use a bidirectional Transformer architecture. Unlike CLM models, MLM models can attend to all tokens in the input sequence during training, allowing them to capture context from both left and right.
- Output Model: A fine-tuned MLM model is better at understanding context and relationships between words in a sequence, making it suitable for tasks like text classification, sentiment analysis, named entity recognition, or question answering.
Sequence-to-Sequence (seq2seq) Modeling:
- Implementation: In seq2seq modeling, the model is trained to generate output sequences based on input sequences. The model consists of two parts: an encoder that encodes the input sequence into a latent representation, and a decoder that generates the output sequence based on this latent representation. The loss is calculated based on the model’s predictions and the actual target output tokens.
- Architecture: Seq2seq models typically use an encoder-decoder architecture, where both the encoder and decoder can be based on the Transformer architecture (e.g., T5, BART) or other architectures like LSTMs (e.g., the original seq2seq model). The encoder processes the input sequence and generates a context representation, while the decoder generates the output sequence based on the encoder’s output and its own hidden state.
- Output Model: A fine-tuned seq2seq model is better at tasks where the model needs to generate coherent output text based on input text, such as summarization, translation, or question answering.
In summary, the main differences between these approaches lie in their training objectives, model architectures, and the tasks they are suited for. CLM models focus on predicting the next token and are good for text generation tasks, MLM models focus on predicting masked tokens and are good for tasks requiring bidirectional context understanding, and seq2seq models focus on generating output sequences based on input sequences and are good for tasks requiring the generation of coherent output text.
MLM parameter in Huggingface selects MLM or CLM
The mlm parameter in the DataCollatorForLanguageModeling class is a boolean flag that indicates whether you want to train a masked language model (MLM) or a causal language model (CLM).
- mlm=True: The data collator will prepare the training data for masked language modeling. In this mode, the input sequences will have a certain percentage of tokens masked, and the model will be trained to predict the original tokens at those masked positions. This is the training objective used by models like BERT.
- mlm=False: The data collator will prepare the training data for causal language modeling, also known as autoregressive language modeling. In this mode, the model will be trained to predict the next token in the sequence given its previous tokens. This is the training objective used by models like GPT.
what are the drawbacks of MLM vs CLM for a LLM chatbot?
Each language modeling technique, Masked Language Modeling (MLM) and Causal Language Modeling (CLM), has its own advantages and drawbacks when used for building a chatbot. Here are some key points to consider:
Masked Language Modeling (MLM):
- Pros:
- MLM can potentially capture bidirectional context, as the model learns to predict masked tokens based on both the preceding and following tokens. This can help the model understand the context more effectively, which might be useful in some chatbot scenarios.
- Cons:
- MLM models like BERT are not designed to generate text autoregressively. While they can be fine-tuned for various NLP tasks, they are not inherently built for text generation like chatbot responses. Adapting MLM models for text generation typically requires additional architectural changes, such as adding a decoder or using a seq2seq model.
- During inference, MLM models cannot predict tokens incrementally, as the training involves predicting masked tokens in parallel. This may result in a less coherent chatbot response, as the model has not been trained to generate text sequentially.
Causal Language Modeling (CLM):
- Pros:
- CLM models like GPT are designed for autoregressive text generation, making them more suitable for chatbot applications. They predict the next token in the sequence given the previous tokens, which aligns with how chatbot responses are generated.
- CLM models can generate coherent and contextually relevant responses because they are trained to predict the next token in a sequence based on the preceding tokens, taking into account the context provided by the input.
Cons:
- CLM models do not explicitly capture bidirectional context, as they only generate tokens based on the preceding tokens. This may lead to a slightly less nuanced understanding of context compared to MLM models, which consider both preceding and following tokens during training.
- Due to their autoregressive nature, CLM models may have slower inference times than MLM models, especially when generating long sequences, as they have to predict each token one at a time.
Which popular LLM’s were trained with DataCollatorForSeq2Seq collator?
DataCollatorForSeq2Seq is typically used for sequence-to-sequence (seq2seq) models, where the model is designed to generate output sequences based on input sequences. Some popular seq2seq models in the Hugging Face Transformers library include:
- BART (Bidirectional and Auto-Regressive Transformers): BART is a denoising autoencoder with a seq2seq architecture, which has been shown to perform well on a variety of natural language understanding and generation tasks. It is pre-trained using a denoising objective, where the model learns to reconstruct the original text from corrupted versions of it.
- T5 (Text-to-Text Transfer Transformer): T5 is a seq2seq model that frames all NLP tasks as text-to-text problems. It is pre-trained using a denoising objective similar to BART. T5 has been shown to perform well on various NLP tasks, including translation, summarization, and question-answering.
- MarianMT: MarianMT is a seq2seq model specifically designed for neural machine translation. It is part of the Marian NMT framework and has been trained on translation tasks for various language pairs.
- Pegasus (Pre-training with Extracted Gap-sentences for Abstractive Summarization): Pegasus is a seq2seq model designed for abstractive summarization. It is pre-trained using a gap-sentence generation task, where important sentences are removed from the input, and the model learns to generate these missing sentences.
- ProphetNet: ProphetNet is a seq2seq model with a novel self-supervised objective called future n-gram prediction. It has been shown to perform well on tasks like abstractive summarization and question generation.
Conclusion
Understanding the differences between CLM, MLM, and Seq2Seq is crucial for selecting the most appropriate training approach for your language model. By following best practices and leveraging the strengths of each method, you can optimize your model’s performance and achieve better results in your NLP tasks.
'DeepLearning > NLP' 카테고리의 다른 글
| [논문 겉핥기 리뷰] LoRA: Low-Rank Adaptation of Large Language Model (0) | 2024.08.31 |
|---|---|
| 한국어는 ROUGE, BLEU metric이 안맞나요? (0) | 2024.08.30 |
| 빔 서치(Beam Search) (0) | 2024.08.29 |
| GPT에게 물어봤습니다. 넌 어떻게 작동하니? (0) | 2024.08.22 |
| 음절, 형태소, 어절, 품사 (0) | 2024.08.16 |
- Total
- Today
- Yesterday
- speaking
- cnn
- Array
- recursion #재귀 #자료구조 # 알고리즘
- 해시
- Transformer
- 파이썬
- Numpy
- English
- classification
- 손실함수
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- Github
- 코딩테스트
- 오블완
- nlp
- Python
- RAG
- 리스트
- git
- Hugging Face
- LLM
- clustering
- PEFT
- LIST
- 티스토리챌린지
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- Lora
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- t5
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |