
Table of Contents
[논문 리뷰] Pre-train, Prompt, and Predict: A Systematic Survey ofPrompting Methods in Natural Language Processing
꼬꼬마코더 2024. 9. 19. 10:391 Two Sea Changes in NLP

Sequence tagging은 **자연어 처리(NLP)**에서 사용하는 기법으로, 주어진 입력 시퀀스(문장이나 단어들)에 대해 각 단어 또는 토큰에 레이블을 붙이는 작업을 의미합니다. 대표적인 예로는 다음과 같은 작업들이 있습니다:
- POS 태깅 (Part-of-Speech Tagging): 각 단어에 품사(명사, 동사, 형용사 등)를 붙이는 작업.
- 예: "I love NLP" → "I/PRP love/VBP NLP/NNP"
- Named Entity Recognition (NER): 문장에서 특정한 개체(사람, 장소, 조직 등)를 식별하고 태그를 붙이는 작업.
- 예: "Barack Obama was born in Hawaii." → "Barack Obama/PER was born in Hawaii/LOC."
- Chunking: 문장에서 문법적인 구(phrase)를 식별하는 작업.
- 예: "He reckons the current account deficit will narrow to only £1.8 billion in September." → "He [NP reckons the current account deficit] [VP will narrow] to only £1.8 billion [PP in September]."
반면에 <sep>와 같은 토큰은 **특별한 토큰(special tokens)**으로, 주로 BERT와 같은 트랜스포머 모델에서 문장의 경계를 구분하거나 다른 역할을 수행하는 데 사용됩니다. 예를 들어, BERT에서 <sep>는 두 문장을 구분하기 위해 사용됩니다.
따라서, sequence tagging은 <sep> 같은 특별한 토큰을 의미하는 것이 아니라, 입력된 시퀀스 내 각 단어에 특정 레이블을 부여하는 작업입니다.
거대한 LLM, 특히 GPT-3나 GPT-4 같은 모델들은 sequence tagging 작업을 거치지 않고도 사용자의 질문을 이해하고, 바로 답을 생성할 수 있습니다. 이 모델들은 기본적으로 텍스트의 문맥과 의미를 학습하며, 특정 태깅 과정 없이도 자연어 처리 작업을 수행할 수 있는 능력을 가지고 있습니다.
왜 그런가요?
거대 언어 모델(LLM)은 다음과 같은 이유로 sequence tagging 같은 중간 단계를 생략하고 바로 작업을 처리할 수 있습니다:
- 언어 모델의 학습 방식:
- LLM은 대규모 데이터에서 텍스트의 구조, 의미, 맥락 등을 학습합니다. 이 때문에 문장의 각 단어의 품사나 태그를 별도로 명시하지 않아도 문장 전체의 의미를 이해할 수 있습니다.
- 이러한 모델들은 문장의 의미를 포괄적으로 이해하고 문맥에 맞게 답을 생성합니다. 즉, 문장의 개별 단어에 대해 태그를 지정하는 sequence tagging 과정을 거치지 않더라도, 그 문장이 무엇을 의미하는지 인식할 수 있습니다.
- 예측 기반의 텍스트 생성:
- GPT 같은 모델은 입력된 질문에 기반해 다음 단어나 문장을 예측하는 방식으로 작동합니다. 이 예측 과정에서, 문장의 의미나 구조를 기반으로 직접적으로 답을 생성합니다. 모델이 개별 단어를 이해할 때 품사 태깅이나 NER을 명시적으로 하지 않더라도 문맥을 통해 이해하고 답을 만들 수 있습니다.
- 사전 학습된 지식:
- LLM들은 방대한 양의 텍스트 데이터를 학습했기 때문에, 일반적인 질문에 대한 대답을 이미 잘 알고 있습니다. 질문의 구문을 별도로 태깅하거나 분석하지 않고도 적절한 답을 제공할 수 있는 이유는 이 사전 학습된 정보 때문입니다.
그렇다면 sequence tagging은 언제 필요할까요?
- 특정 태깅 작업이 필요할 때 (예: NER, 품사 태깅)나 텍스트의 각 부분을 구체적으로 분석해야 할 때는 sequence tagging이 필요합니다. 하지만 질문을 이해하고 답을 생성하는 과정에서는 이러한 태깅이 반드시 필요하지 않습니다.
- 특히 거대 LLM들은 대규모로 훈련된 덕분에, 이러한 중간 단계를 생략하고도 문맥과 의미를 기반으로 답을 바로 생성할 수 있습니다.
요약하자면, 거대 LLM은 별도의 sequence tagging 작업 없이도 질문을 이해하고 답을 생성할 수 있는 능력이 있습니다.
NLP의 네 가지 패러다임
이 표는 NLP의 네 가지 패러다임을 나타내고 있으며, 각각의 패러다임에 따라 엔지니어링 방식과 언어 모델(LM) 및 NLP 작업(예: 분류, 시퀀스 태깅, 생성) 간의 관계를 설명하고 있습니다. 각 패러다임에 대한 설명은 다음과 같습니다:
a. 완전 감독 학습 (Fully Supervised Learning, Non-Neural Network)
- Engineering: 비신경망 기반의 완전한 감독 학습 방식에서는 모델이 단어의 정체성, 품사, 문장 길이와 같은 **특징(feature)**을 학습합니다.
- Task Relation: 이 경우, 각 작업(Classification, Sequence Tagging, Generation) 간에는 별도의 연결이 없습니다. 즉, 태스크별로 모델이 개별적으로 학습됩니다.
b. 완전 감독 학습 (Fully Supervised Learning, Neural Network)
- Engineering: 신경망 기반의 완전 감독 학습에서는 **신경망 아키텍처(예: CNN, RNN, Self-attention)**를 사용하여 학습합니다.
- Task Relation: 각 작업 간에 연결이 없으며, 역시 각 작업은 개별적으로 학습됩니다. 다만 신경망을 사용하기 때문에 구조는 더 복잡해집니다.
c. 프리트레이닝 후 파인튜닝 (Pre-train, Fine-tune)
- Engineering: 이 패러다임에서는 목표(objective) 기반의 학습을 진행합니다. 예를 들어, **마스크드 언어 모델링(Masked Language Modeling)**이나 **다음 문장 예측(Next Sentence Prediction)**을 통해 프리트레이닝을 한 후, 각 태스크에 맞게 모델을 파인튜닝합니다.
- Task Relation: 이 경우, 프리트레이닝된 언어 모델이 각 태스크(분류, 태깅, 생성)를 위해 파라미터를 공유하면서 사용됩니다. 프리트레이닝된 모델을 활용해 파인튜닝하는 방식으로, 여러 NLP 작업에 적용할 수 있습니다.
d. 프리트레이닝, 프롬프트, 그리고 예측 (Pre-train, Prompt, Predict)
- Engineering: 이 방법에서는 **프롬프트(prompt)**를 사용합니다. 예를 들어 클로즈(cloze) 작업이나 **프리픽스(prefix)**를 활용하여 모델에 지시를 내리거나 조건을 제공하고, 이를 기반으로 모델이 직접 예측을 수행합니다.
- Task Relation: 여기서는 프롬프트를 통해 언어 모델을 다양한 태스크에 적용할 수 있습니다. 프롬프트는 텍스트 형태로 주어지며, 이를 통해 분류, 태깅, 생성 등의 작업이 하나의 모델에서 수행됩니다. 다양한 태스크 간의 연결이 가능하며, 프롬프트가 중요한 역할을 합니다.
Key Takeaways (중요한 점들):
- a와 b 패러다임에서는 각 작업 간의 연결이 없으며, 작업별로 모델을 따로 학습합니다. 비신경망과 신경망의 차이점은 있지만, sequence tagging, classification, text generation 등의 작업이 서로 분리되어 있습니다.
- c와 d 패러다임에서는 프리트레이닝된 언어 모델을 사용하여 여러 작업을 처리합니다. 특히 c는 파인튜닝을 통해 작업별로 맞춤형 모델을 만드는 방식이고, d는 프롬프트를 통해 하나의 모델에서 다양한 작업을 처리할 수 있도록 합니다.
특히 d 패러다임에서 프롬프트의 사용이 핵심적인 역할을 하며, 여러 NLP 작업을 통합하여 처리할 수 있는 강력한 방식입니다.
2 A Formal Description of Prompting
2.1 Supervised Learning in NLP
2.2 Prompting Basics
2.2.1 Prompt Addition
2.2.2 Answer Search
2.2.3 Answer Mapping
2.3 Design Considerations for Prompting
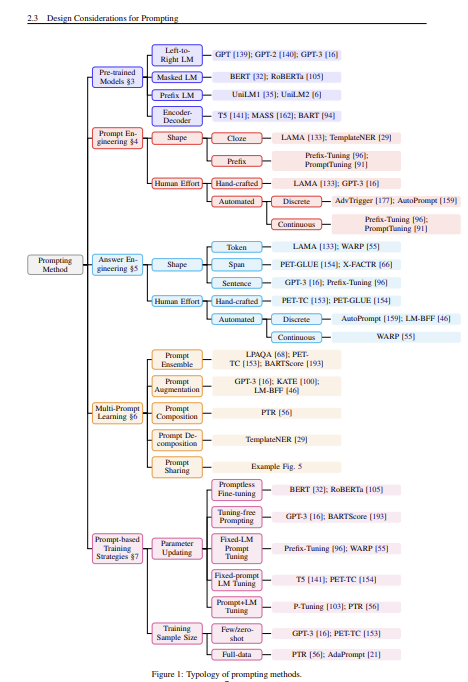
1. Pre-trained Models (프리트레인 모델)
- 왼쪽 상단에는 프리트레인된 모델의 유형이 나열되어 있습니다. 각 유형은 언어 모델의 훈련 방식에 따른 구분입니다.
- Left-to-Right LM: GPT 같은 모델들이 여기 포함되며, 텍스트를 왼쪽에서 오른쪽으로 예측합니다.
- Masked LM: BERT와 같이 문장에서 일부 단어를 마스킹하고 나머지 문맥을 통해 마스킹된 단어를 예측하는 방식입니다.
- Prefix LM: Prefix 형태의 입력을 통해 모델을 학습시키는 방식입니다.
- Encoder-Decoder: T5, BART 같은 모델로, 인코더와 디코더 구조를 통해 입력 텍스트를 처리하고 출력합니다.
2. Prompt Engineering (프롬프트 엔지니어링)
- 프롬프트 엔지니어링은 모델이 더 효과적으로 텍스트를 처리할 수 있도록 입력을 설계하는 방법을 말합니다. **Prompt Shape(프롬프트 모양)**과 **Answer Engineering(답변 설계)**으로 구분되어 있습니다.
- Shape (모양):
- Cloze: 기존 문장에서 일부를 빈칸으로 만들어 모델이 빈칸을 채우도록 하는 방식(LAMA, TemplateNER 등).
- Prefix: 문장 앞에 접두어를 붙여 맥락을 제공하는 방식.
- Human Effort (사람이 직접 프롬프트를 설계):
- Hand-crafted: 사람이 직접 템플릿을 디자인합니다(LAMA, PET-GLUE 등).
- Automated: 자동화된 도구나 기법을 사용해 프롬프트를 생성(AdvTrigger, AutoPrompt 등).
- Continuous: 연속적인 벡터 공간에서 프롬프트를 사용하는 방식(Prefix-Tuning, LM-BFF 등).
- Answer Engineering (답변 설계):
- Shape (답변의 형태):
- Token: 하나의 토큰으로 답변을 생성.
- Span: 특정 텍스트 구간을 답으로 추출.
- Sentence: 완전한 문장 형태로 답변을 생성.
- Human Effort:
- Hand-crafted: 사람이 직접 답변을 구성하는 방식.
- Automated: 자동화된 답변 생성을 위한 기법.
- Automated 방법:
- Discrete: 고정된 텍스트 형식을 사용한 답변 생성 방식(PE-TC, AutoPrompt 등).
- Continuous: 연속적인 벡터 표현을 사용하는 방식(WARP).
- Shape (답변의 형태):
3. Multi-Prompt Learning (다중 프롬프트 학습)
- Prompt Ensembling: 여러 프롬프트를 조합하여 결과를 개선하는 방식(GPT-3, LM-BFF 등).
- Prompt Augmentation: 프롬프트를 추가하여 학습 데이터의 다양성을 확보하는 방법.
- Prompt Sharing: 여러 작업에 공통적으로 사용할 수 있는 프롬프트를 공유하는 방식.
4. Prompt-based Training Strategies (프롬프트 기반 학습 전략)
- 프롬프트 기반으로 모델을 학습시키는 다양한 전략들이 나열되어 있습니다.
- Parameter Updating (파라미터 업데이트 방법):
- Promptless Fine-tuning: 프롬프트 없이 파인튜닝을 진행하는 방식.
- Tuning-free Prompting: 모델의 파라미터를 업데이트하지 않고 프롬프트만으로 학습.
- Fixed-LM Prompt Tuning: 모델의 파라미터는 고정시키고 프롬프트만 튜닝.
- Prompt+LM Tuning: 프롬프트와 모델의 파라미터를 함께 업데이트.
- Parameter Updating (파라미터 업데이트 방법):
- Training Sample Size (샘플 크기에 따른 학습 방법):
- Few/Zero-shot Learning: 아주 적은 수의 샘플이나 샘플 없이 학습하는 방법.
- Full-data Learning: 전체 데이터를 사용하여 학습하는 방식.
3 Pre-trained Language Models
3.1 Training Objectives
3.2 Noising Functions
3.3 Directionality of Representations
3.4 Typical Pre-training Methods
3.4.1 Left-to-Right Language Model
3.4.2 Masked Language Models
3.4.3 Prefix and Encoder-Decoder
4 Prompt Engineering
4.1 Prompt Shape
4.2 Manual Template Engineering
4.3 Automated Template Learning
4.3.1 Discrete Prompts
4.3.2 Continuous Prompts
5 Answer Engineering
5.1 Answer Shape
5.2 Answer Space Design Methods
5.2.1 Manual Design
5.2.2 Discrete Answer Search
5.2.3 Continuous Answer Search
6 Multi-Prompt Learning
6.1 Prompt Ensembling
6.2 Prompt Augmentation
6.3 Prompt Composition
6.4 Prompt Decomposition
7 Training Strategies for Prompting Methods
7.1 Training Settings
7.2 Parameter Update Methods
7.2.1 Promptless Fine-tuning
7.2.2 Tuning-free Prompting
7.2.3 Fixed-LM Prompt Tuning
7.2.4 Fixed-prompt LM Tuning
7.2.5 Prompt+LM Tuning
8 Applications
8.1 Knowledge Probing
8.2 Classification-based Tasks
8.3 Information Extraction
8.4 “Reasoning” in NLP
8.5 Question Answering
8.6 Text Generation
8.7 Automatic Evaluation of Text Generation
8.8 Multi-modal Learning
8.9 Meta-Applications
8.10 Resources
9 Prompt-relevant Topics
10 Challenges
10.1 Prompt Design
10.2 Answer Engineering
10.3 Selection of Tuning Strategy
10.4 Multiple Prompt Learning
10.5 Selection of Pre-trained Models
10.6 Theoretical and Empirical Analysis of Prompting
10.7 Transferability of Prompts
10.8 Combination of Different Paradigms
10.9 Calibration of Prompting Methods
11 Meta Analysis
11.1 Timeline
11.2 Trend Analysis
12 Conclusion
A Appendix on Pre-trained LMs
A.1 Evolution of Pre-trained LM Parameters
A.2 Auxiliary Objective
A.3 Pre-trained Language Model Families
'DeepLearning > NLP' 카테고리의 다른 글
| [LLM] LLM 모델이 LM 모델과 달라진 점 (0) | 2024.09.19 |
|---|---|
| [LLM] LM에서 LLM으로 발전하는 과정에서의 주요 변화 (1) | 2024.09.19 |
| [LLM] 모델이 학습하는 Fine-tuning의 다양한 방법 (0) | 2024.09.19 |
| [LLM] 모델이 학습하는 방법: fine-tuning/in-context learning/pre-training (0) | 2024.09.19 |
| gpt 너는 내가 하는 말의 핵심을 어떻게 파악하는거야? (1) | 2024.09.17 |
- Total
- Today
- Yesterday
- English
- 손실함수
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- speaking
- classification
- 오블완
- Github
- clustering
- Array
- Hugging Face
- 해시
- t5
- Python
- 티스토리챌린지
- Transformer
- cnn
- RAG
- 파이썬
- PEFT
- 코딩테스트
- 리스트
- Numpy
- Lora
- git
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- LLM
- LIST
- recursion #재귀 #자료구조 # 알고리즘
- nlp
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |