

Table of Contents
블랙박스 모델
모델이 explainability도 높고 performance도 높으면 좋지만 explainability는 낮은데 performance만 좋은 경우들이 있습니다. 이런 경우를 우리는 모델이 블랙박스다 라고 표현합니다.

모델이 블랙박스라는 뜻은 그 모델의 내부 작동 방식이 불투명하거나 이해하기 어렵다는 의미입니다. 주로 인공지능이나 머신러닝 모델에 대해 사용되는 용어로, 입력과 출력 사이의 관계는 알 수 있지만, 그 과정이 어떻게 이루어지는지는 명확하지 않거나 설명하기 어렵다는 점을 강조합니다.
블랙박스 모델은 다음과 같은 특징이 있습니다:
- 불투명성: 모델이 예측을 어떻게 하는지 내부 구조나 과정을 이해하기 어렵습니다.
- 복잡성: 모델이 매우 복잡해서 사람이 일일이 분석하기 어려운 경우가 많습니다. 예를 들어, 딥러닝의 신경망 모델은 많은 층과 뉴런들로 이루어져 있어 이해하기 어려울 수 있습니다.
- 설명력 부족: 모델이 왜 특정한 결정을 내렸는지 설명하기 어려운 경우가 많습니다. 이는 모델의 신뢰성과 투명성 문제로 이어질 수 있습니다.
블랙박스 모델의 반대 개념은 "화이트박스" 또는 "해석 가능한 모델"로, 이러한 모델은 내부 작동 방식이 명확하게 드러나고 사람이 이해하고 설명할 수 있는 특징을 가지고 있습니다. 예를 들어, 선형 회귀나 의사결정 나무와 같은 모델은 그 작동 원리가 명확히 드러나고 이해하기 쉬운 편입니다.
XAI: Explainable AI
그래서 XAI: eXplainable Artificial Intelligence: Explainable AI 라는 개념이 중요시되고 있습니다.
XAI (Explainable AI)란 "설명 가능한 인공지능"을 의미하며, 인공지능 및 머신러닝 모델의 결정을 사람이 이해하고 신뢰할 수 있도록 만드는 기술과 방법론을 포함합니다. XAI는 블랙박스 모델의 단점을 보완하고, AI 시스템의 투명성과 신뢰성을 높이기 위한 다양한 접근 방식을 제공합니다. 주요 목적은 모델이 내린 결정에 대한 이해를 돕고, 이를 통해 더 나은 의사결정을 지원하는 것입니다.
XAI의 주요 목표와 특징은 다음과 같습니다:
- 해석 가능성: 모델이 어떻게 작동하는지, 왜 특정 결정을 내렸는지 설명할 수 있어야 합니다.
- 투명성: 모델의 내부 구조와 동작 방식이 명확하게 드러나야 합니다.
- 신뢰성: 사용자와 이해관계자가 모델의 결정을 신뢰할 수 있어야 합니다.
- 공정성: 모델의 결정이 공정하고, 특정 집단에 편향되지 않도록 해야 합니다.
- 책임성: 모델의 결정을 추적하고, 잘못된 결정에 대해 책임을 질 수 있도록 해야 합니다.
XAI 기법에는 다양한 접근 방식이 있습니다:
- 모델 내재적 해석 가능성: 모델 자체가 해석 가능하도록 설계하는 것. 예를 들어, 결정 트리, 선형 회귀, 로지스틱 회귀 등은 본질적으로 해석 가능한 모델입니다.
- 포스트 호크 설명 기법: 블랙박스 모델을 설명하기 위해 추가적인 분석을 수행하는 방법. 여기에는 LIME (Local Interpretable Model-agnostic Explanations), SHAP (SHapley Additive exPlanations) 등이 포함됩니다.
- 시각화 도구: 모델의 동작과 결정을 시각적으로 표현하여 이해를 돕는 도구. 예를 들어, 주성분 분석(PCA) 시각화, 결정 경계 시각화 등이 있습니다.
XAI는 의료, 금융, 법률 등 고도의 신뢰성과 설명력이 요구되는 분야에서 특히 중요합니다. AI 시스템이 내리는 결정이 사람의 생명이나 재산에 영향을 미치는 경우, 그 결정 과정을 이해하고 설명할 수 있어야 하기 때문입니다.

LIME (Local Interpretable Model-agnostic Explanations)와 SHAP (SHapley Additive exPlanations)는 머신러닝 모델의 예측을 설명하기 위한 두 가지 인기 있는 기법입니다. 이 두 방법은 블랙박스 모델을 해석 가능하게 만들어 주는 XAI (Explainable AI) 기술의 중요한 도구로 사용됩니다.
LIME (Local Interpretable Model-agnostic Explanations)
LIME은 개별 예측을 설명하는 데 중점을 두는 기법입니다. 이 방법은 모델이 특정 입력에 대해 내린 예측을 이해하기 쉽게 설명해 줍니다.
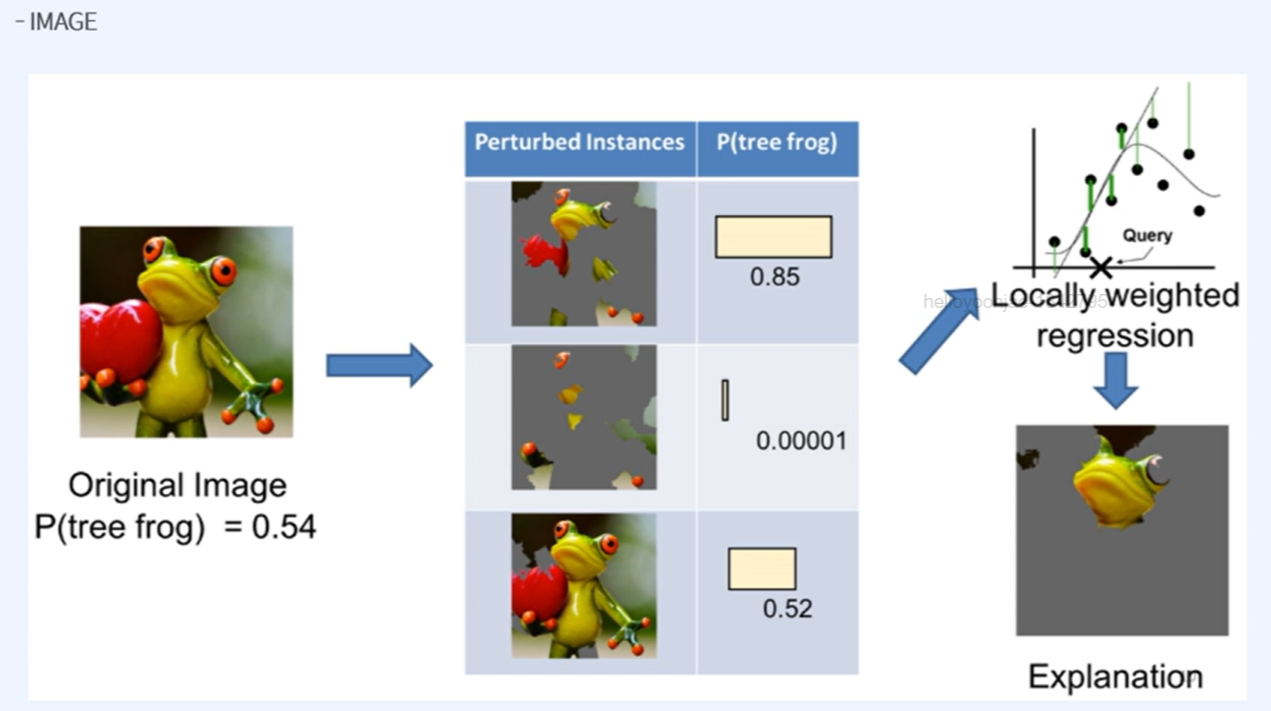
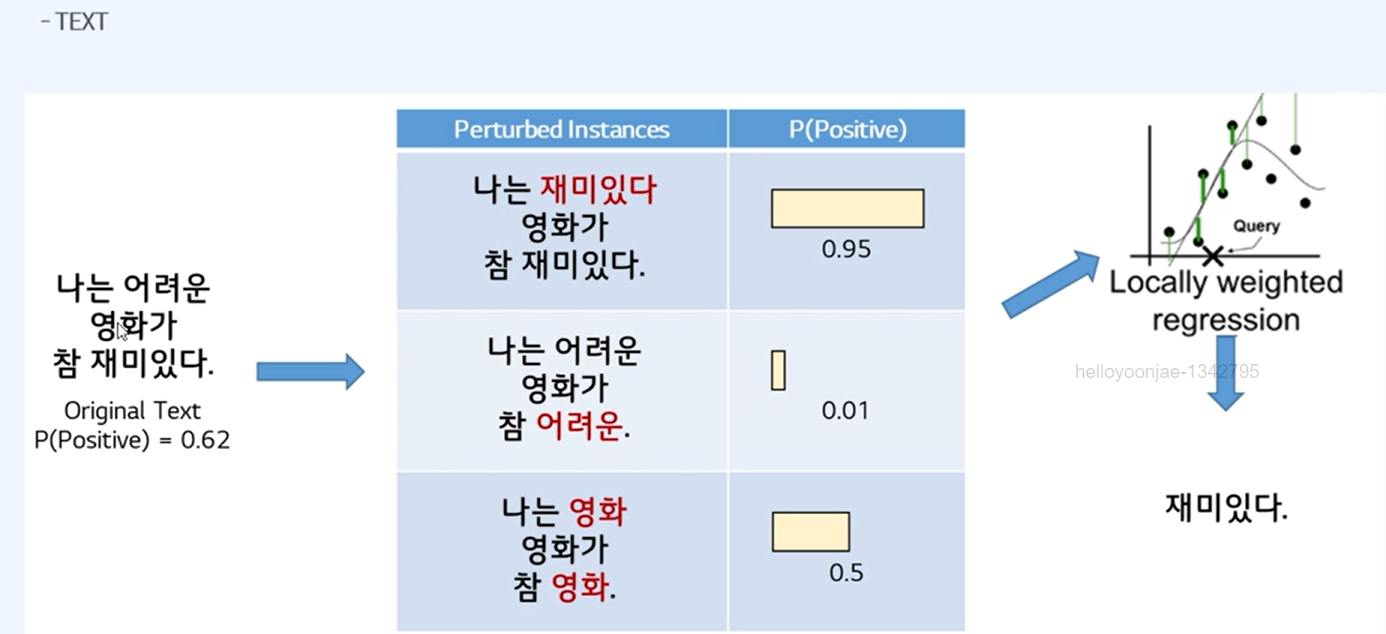
원리:
- 지역적 선형 모델: LIME은 관심 있는 특정 예측 점 근처에서 모델을 선형 모델로 근사합니다. 이는 전체 복잡한 모델을 단순화하여 특정 지역에서의 동작을 이해하기 쉽게 합니다.
- Perturbation: 입력 데이터를 약간 변형하여 여러 샘플을 생성합니다.
- 가중치 부여: 변형된 샘플에 대해 원래 모델의 예측을 수행하고, 이 예측에 대해 가중치를 부여하여 선형 모델을 학습합니다.
- 설명 제공: 학습된 선형 모델을 사용하여 원래 예측에 대한 설명을 제공합니다.
장점:
- 모델에 무관하게 적용 가능 (Model-agnostic).
- 특정 예측에 대한 이해를 돕는 직관적인 설명 제공.
단점:
- 선형 근사는 복잡한 비선형 모델의 경우 부정확할 수 있음.
- 지역적 설명이므로 전체 모델의 동작을 이해하는 데는 한계가 있음.
SHAP (SHapley Additive exPlanations)
SHAP는 게임 이론에 기반한 접근 방식으로, 각 피처가 예측에 기여하는 정도를 공정하게 분배합니다.
원리:
- Shapley 값: 협력 게임 이론에서 도입된 개념으로, 각 플레이어(피처)가 전체 결과에 기여하는 가치를 공정하게 계산합니다.
- Additive Feature Attribution: SHAP는 모델의 예측을 각 피처의 기여도 합으로 나타내는 선형 모델로 간주합니다.
- 설명 제공: 각 피처의 Shapley 값을 계산하여 예측에 대한 기여도를 나타냅니다. 이는 특정 피처가 예측에 어떻게 영향을 미치는지 명확하게 보여줍니다.
장점:
- 이론적으로 공정하고 일관된 피처 중요도 제공.
- 전체 모델에 대한 글로벌 설명과 특정 예측에 대한 로컬 설명 모두 가능.
단점:
- 계산 비용이 높음 (특히 많은 피처가 있는 경우).
- 모델의 복잡도에 따라 Shapley 값 계산이 어려울 수 있음.
요약
- LIME: 특정 예측에 대한 지역적, 직관적인 설명 제공. 모델에 구애받지 않고 적용 가능. 다만, 선형 근사로 인해 복잡한 모델을 부정확하게 설명할 수 있음.
- SHAP: 게임 이론에 기반한 공정한 피처 중요도 제공. 글로벌 및 로컬 설명 모두 가능. 다만, 계산 비용이 높고, 복잡한 모델의 경우 계산이 어려울 수 있음.
이 두 기법은 각기 다른 장단점을 가지고 있으며, 사용자는 자신의 필요에 맞춰 적절한 방법을 선택하여 블랙박스 모델의 예측을 해석하고 설명할 수 있습니다.
'ML' 카테고리의 다른 글
| [패스트캠퍼스] Upstage AI Lab 3기 학습 블로그_ ML 프로젝트 기본 이론 : 머신러닝 클러스터링 평가지표 Clustering Evaluation Metrics (0) | 2024.05.31 |
|---|---|
| Clustering 클러스터링 (1) | 2024.05.31 |
| Ensemble > Boosting: Gradient Boosting Machine(GBM), XGBoost, LightGBM, CatBoost, NGBoost (0) | 2024.05.30 |
| Adaboost(Adaptive Boosting) (0) | 2024.05.30 |
| Model Explanation 모델설명 (1) | 2024.05.30 |
- Total
- Today
- Yesterday
- cnn
- git
- PEFT
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- 티스토리챌린지
- speaking
- 리스트
- 해시
- 오블완
- clustering
- Array
- 코딩테스트
- Python
- Hugging Face
- 손실함수
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- classification
- Numpy
- nlp
- Lora
- RAG
- English
- recursion #재귀 #자료구조 # 알고리즘
- 파이썬
- LIST
- t5
- Github
- LLM
- Transformer
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |