

Table of Contents
[Document Type Classification | 문서 타입 분류] VISION 프로젝트 개인회고
꼬꼬마코더 2024. 8. 12. 18:171. 프로젝트 개요
A. 개요 : https://stages.ai/en/competitions/319/leaderboard/list

B. 환경: Upstage에서 제공하는 remote 서버연결
| GPU | CPU | Memory |
| RTX 3090 / 24 GB | 10 thread | 60G |
2. 프로젝트 팀 구성 및 역할
2-1. 매일 11시 어제 한 것, 유효한 부분, 내일 진행할 부분에 대해 공유, 모델학습실험기록지를 엑셀로 공유
2-2. 역할분담
진행속도가 빠른 사람이 실험결과 공유해주고, 후발주자가 성능 올릴 수 있는 다양한 실험 진행
3.프로젝트 수행 절차 및 방법
3-1. 데이터 전처리:
Augmentation을 강하게 적용, 200배 증강하여 데이터 수 1570*200=314000으로 진행, 나는 100배로 진행.
Augraphy의 경우 테스트셋에 사용된 것 같지 않다고 판단 적용하지 않음 --> 향후 최종 발표에서 모든 조들이 Augrapy를 적용했고 강사님도 Augraphy를 적용하지 않은 것이 신기하다고 하셔서 판단착오였음WDNX4 전처리 진행, 성능향상에 도움이 되었음.Class Imbalance처리함. 성능향상에 도움이 되었음.
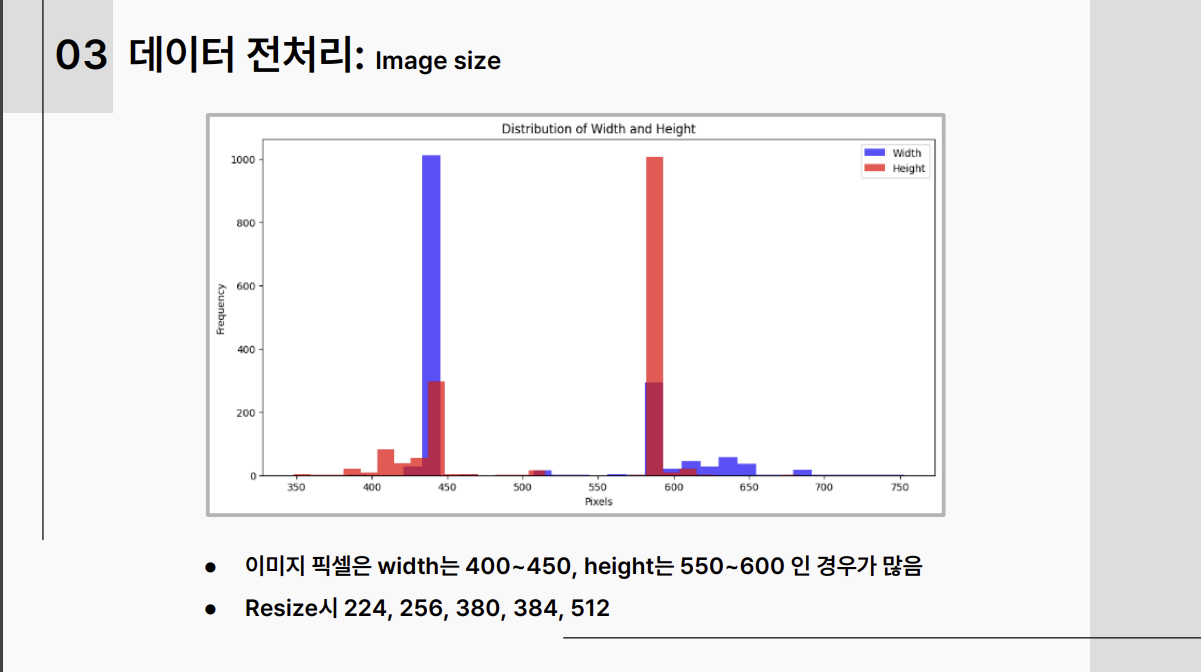
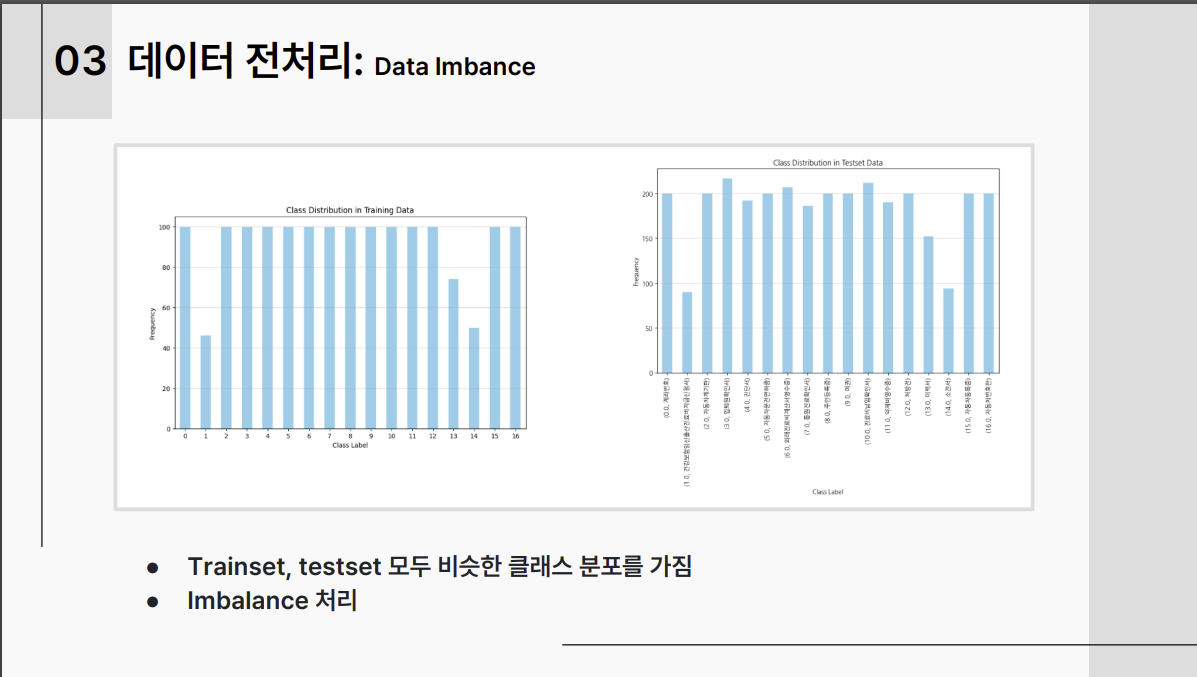
3-2. 모델 셀렉션:
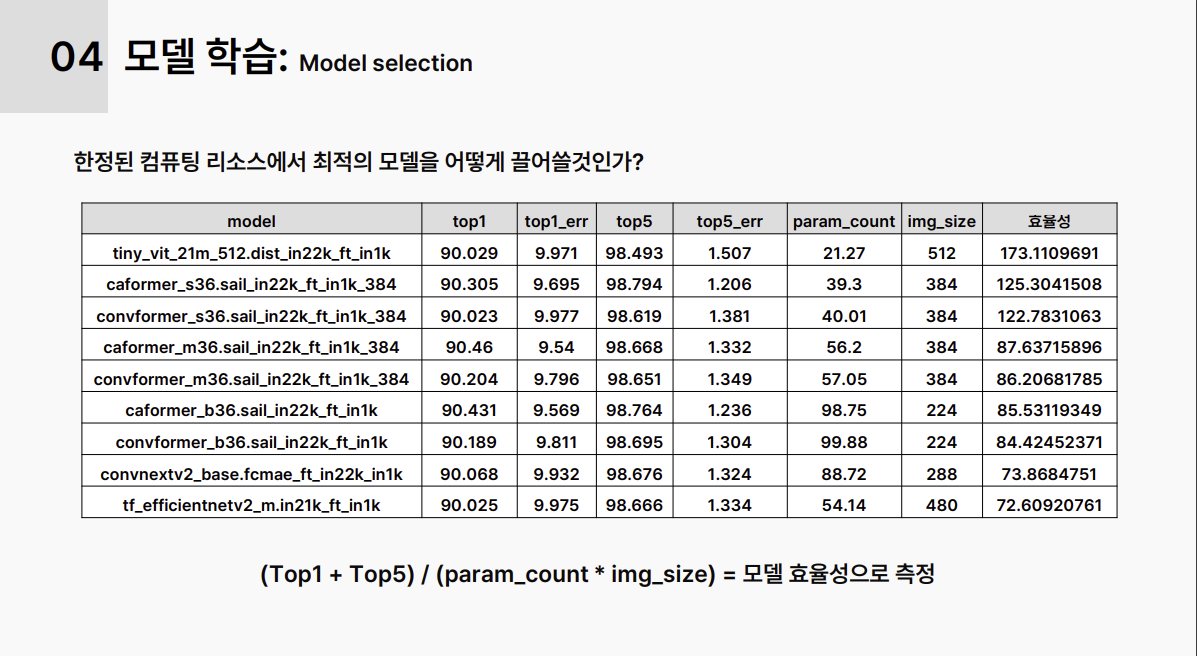
F1 score가 높은 timm라이브러리 모델들 중 param수가 적고 img_size가 작을수록 효율성이 높은 것으로 판단, 여러 모델을 실험함. EfficientNet 시리즈 중 img_size가 큰 모델이 주효했음, Tiny ViT 모델도 성능이 좋았음.
top1: top1의 정확도/ top5: top5개의 정확도(확실하지 않음)
3-3.Dataset Split
개인적으로는 8:2 로 stratified valid test 로 최종 진행하였고, 5 k-fold의 경우 지나치게 느려지는 속도때문에 진행하지 않음. valid를 사용시 에포크 학습을 언제까지 할 지 도움을 주지만 최종 F1 score의 정확도를 보장하는 것은 아니었음. 0.4 이상 차이남. vision 프로젝트에서는 큰 메리트를 보지 못함.
3-4.Hyperparameter Tuning
Drop-out은 반드시 적용해야 성능이 올라갔음. img_size 클수록 성능이 훅 올라감.
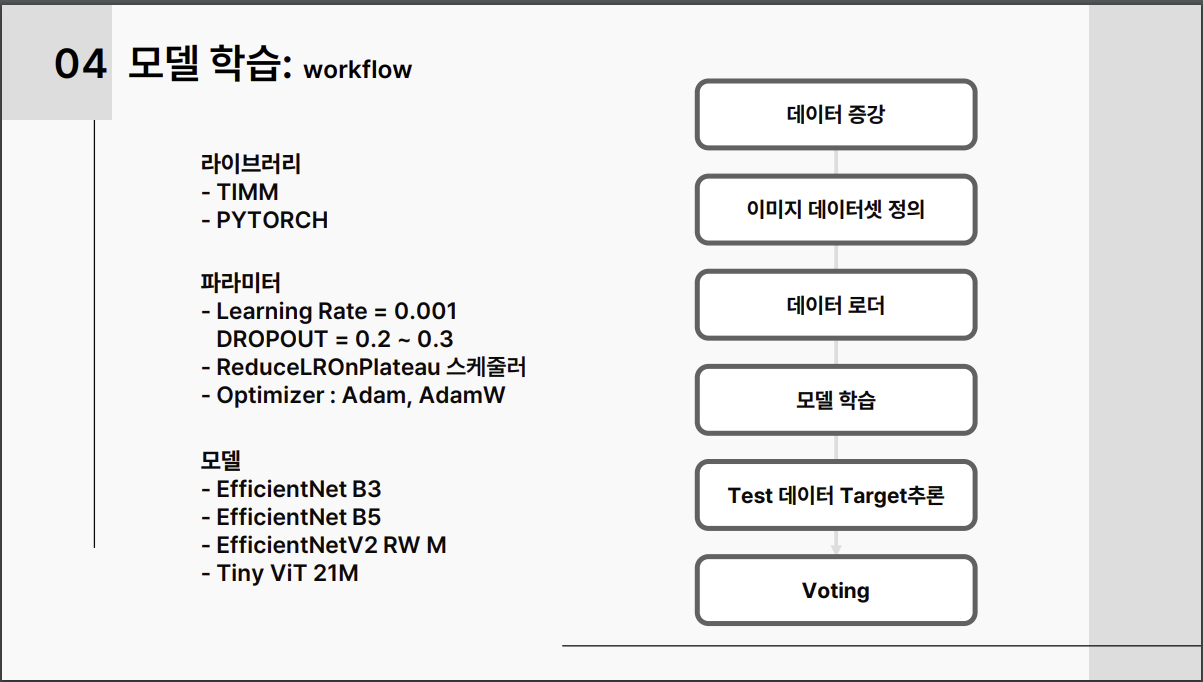
3-5. 기타 주효한 기법들
TTA: 0.94부터는 효과 없었음, 0.91정도에서는 0.03이나 올라갔음.
Soft Voting: Hard Voting보다 효과 좋았음.
OCR: 모델만으로는 95점에서 한계가 봉착했기 때문에 모델이 분류한 target 3,4,7,14에 대해서만 EasyOCR을 적용하여 97.5점까지 끌어올림. 그 이후 98점까지는 OCR이 이상하게 내뱉는 키워드도 입력시켜 강제로 점수를 끌어올림. --> 처음부터 Upstage OCR을 사용했으면 좋았을텐데 프로젝트 끝나갈때쯤 아이디어가 나와서 적용을 못함.

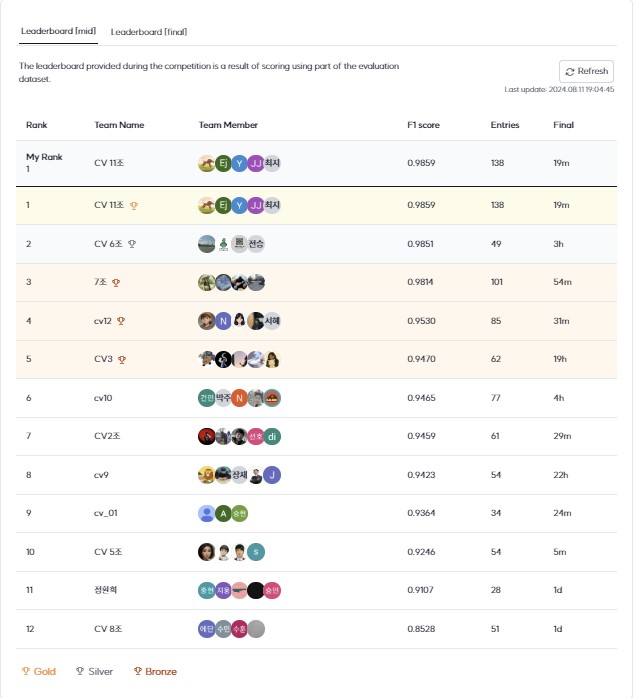
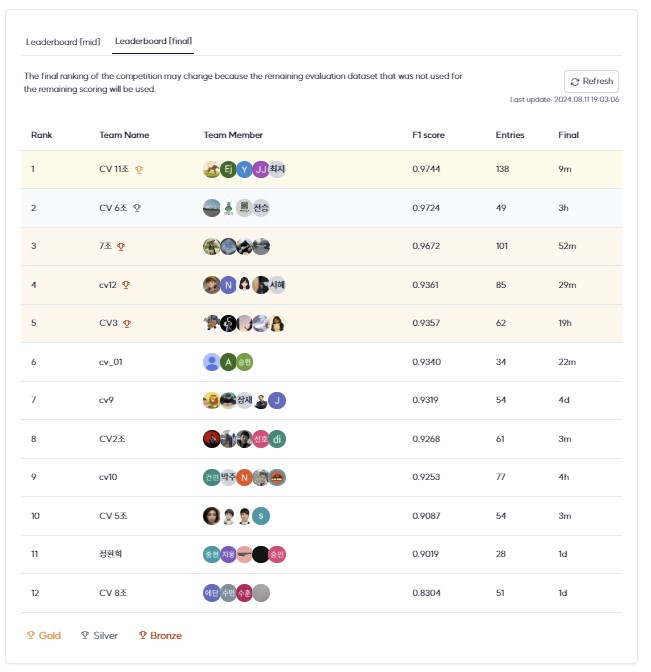
3-6.최종 순위 및 평가지표 결과
mid 0.9859 final 0.9744 로 1위를 하였으나, 2,3위 팀이 모델자체만으로 mid 0.98대 final 0.97대를 달성하여 충격을 받음. 2,3위 팀들은 focal loss, triplet? 과 같은 알지 못하는 용어들로 발표함. 당시에는 정확히 이해하지 못하였고, 발표 후 제공받은 발표자료와 깃 코드를 가지고 재검토함.

4. 3위 팀, 7조의 실험에 대한 생각
Data Augmentation
이 부분은 우리 조와 크게 다른 것 같지 않음.

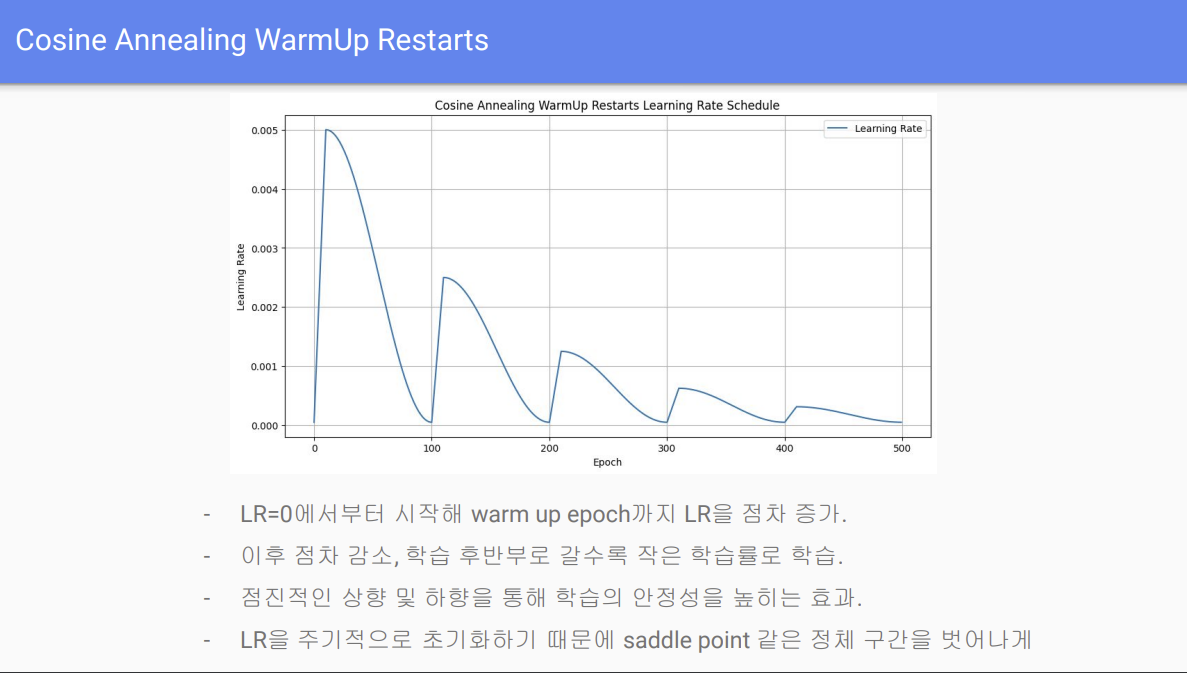
Cosine Annealing WarmUp Restart
발표자료에서 7조는 Cosine Annealing WarmUp Restart 라는 learning rate를 사용했다고 함. online증강방식의 단점을 극복하는데 도움이 되었다고 하는데 offline과 online증강방식은 아무런 차이가 없을텐데 뭔가 실험을 잘못한듯함. 송원호 강사님도 그렇게 말씀하셨음. 이런 특이한 learning rate가 있다는 사실을 알아서 좋았으며 다음에 사용시 도움이 될 것 같음.
Crop
나도 crop진행해서 실험했지만 실험결과가 나빠져서 사용하지 않았음. 역시나 ppt를 살펴보니 EfficientNet B3 에서 B5로 실험해서 이미지 사이즈가 커졌기 때문에 점수가 올라간 것이지 Crop을 해서 올라간 것이 아님.

Grad-CAM
문서작업에 왜 Grad-CAM을 사용하는거지? 많은 조들이 Grad-CAM을 확인차 사용하던데 송원호 강사님도 말씀하셨다시피 문서에는 맞지 않는 기법이라고 생각함.

Calibration model과 앙상블
오답이 발생한 클래스만으로 따로 학습하여 앙상블을 했더니 94.59 --> 96.47이 되었다고 함. 이 방법은 써볼만한 것 같음.

Model 교체
나는 EfficientNetV2를 써볼 생각을 왜 못했을까? trainf1이 빠르게 포화되었다는 것이 무슨 말일까? 나는 7조 발표자인 분에게 "train f1이 빠르게 포화되었다는 것이 1에포크에서부터 높은 score에 빠르게 도달했다는 의미일까요? 저희 조는 1epoch만에 train f1 score 가 0.95 이상 도달하였습니다. 이 이유가 멘토님의 말처럼 데이터의 특정한 특징에 과적합되어서라면 이 말은 1번. 데이터셋의 증강을 테스트셋에 제대로 맞추지 못했다는 뜻일까요? 아니면 2번.더 강력한 모델, 즉 v2를 써야 한다는 뜻일까요?" 라고 문의를 했음.
- 1epoch만에 높아지는 것은 아니고 5epoch 내에 90점 이상에 도달하는 것이었습니다.
- 또한 학습을 계속 진행하더라도 최대 95점 이상을 넘어가지 못하는 현상이 있었는데, 멘토님은 이러한 현상을 "데이터의 특정한 특징에 모델이 과적합하게 되는 것일 수 있다."라고 조언을 주셨고 모델의 규모를 확장시켜보면 더 나아질 수 있을 것이라고 하셨습니다.
- 따라서 기존에 사용하던 efficientnet보다 더 규모가 큰 efficientnet v2를 실험해봤고 문제가 있었던 부분이 꽤 완화되는 모습을 보였습니다.
- 일단 저희도 efficientnet v2가 어떤 구조와 기술적인 특징을 가지는지 이해하고 사용한 것은 아닙니다. 단지 efficientnet-B5보다 더 큰 모델 후보들을 찾다가 사용해본 것이라 기술적인 것 때문인지는 확실하지 않습니다.
- 공유해주신 결과에 대한 제 주관적인 해석인데
-
더보기1 epoch에 95%에 도달했다면 데이터셋의 증강을 테스트셋에 제대로 맞추지 못했다기보다 증강의 옵션 수가 작아 다양성이 부족하고, 그에 따라 모델 입장에서 데이터가 너무 쉬울 수도 있습니다.
-
더보기결국 200배 증강을 했다고 하더라도 데이터 증강 파이프라인에서 증강 옵션의 수(예를 들어 rotate, flip만 적용했다면 두 개)가 너무 작다면 파생되는 양이 아무리 많아도 단조로운 패턴일 뿐입니다.
-
더보기물론 이것은 "대회"이기 때문에 어디까지나 테스트 데이터의 분포에 맞게 학습을 하면 되므로 해당 분포에 맞는 다양성이 필요하다고 생각합니다. 만약 이게 대회가 아니라 서비스였다면 "일반화 성능"을 높히기 위해 다양성을 크게 넓히는 것이 더 좋겠죠?
-
더보기또 augraphy는 테스트 이미지에서 보이는 점박이(?)형 노이즈나 패턴 노이즈등을 제공하기 때문에 필수는 아니지만 왠만하면 적용하는 것이 리더보드 점수 향상에 도움이 될 것 같아요.
-
더보기저희 실험상 학습 데이터가 충분히 테스트셋 분포와 유사하다면 resnet만으로도 92%에 도달하는 것이 가능했습니다. 따라서 일단 모델의 규모를 키우기 보다 학습의 안정성을 먼저 확보하는 편이 더 좋아보입니다.
EfficientNetV2의 특징:
- 네트워크 아키텍처: EfficientNetV2는 EfficientNet의 후속 모델로, 네트워크 아키텍처를 자동으로 검색하는 NAS(Neural Architecture Search) 기술을 통해 설계되었습니다. 기존 EfficientNet의 확장판으로, 더 작은 모델에서 더 빠른 속도를 제공하면서도 높은 정확도를 유지합니다.
- Gradual Learning: EfficientNetV2는 점진적 학습(Gradual Learning)을 도입하여, 네트워크의 복잡도를 점진적으로 증가시킴으로써 학습 속도를 향상시킵니다.
- Fused-MBConv: EfficientNetV2는 MobileNetV3에서 도입된 Fused-MBConv 레이어를 활용하여, 작은 이미지에서의 성능을 최적화합니다.
7조 발표자 분과의 대화를 다시 곰곰이 생각해보면, 결국 뛰어난 모델이 따로 특정되어 있는 것은 아니고, 이미지 사이즈를 크게 했을 경우와 데이터셋의 aug를 테스트셋이 잘 학습할 수 있도록 셋팅한 것이 주효한 부분이라는 생각이 든다. 왜냐하면 발표자료에도 나와 있듯이 v2가 아니라 b5 로 성능을 대폭 향상했기 때문이다.

OCR 효과못봄, img_size= 613으로 증가시킴
이미지 사이즈를 613까지 증가시켰는데도 서버가 터지지 않았다니, 우리 11조도 512까지는 도전했는데 더 큰 사이즈에도 도전해볼 걸 아쉬움이 남음.

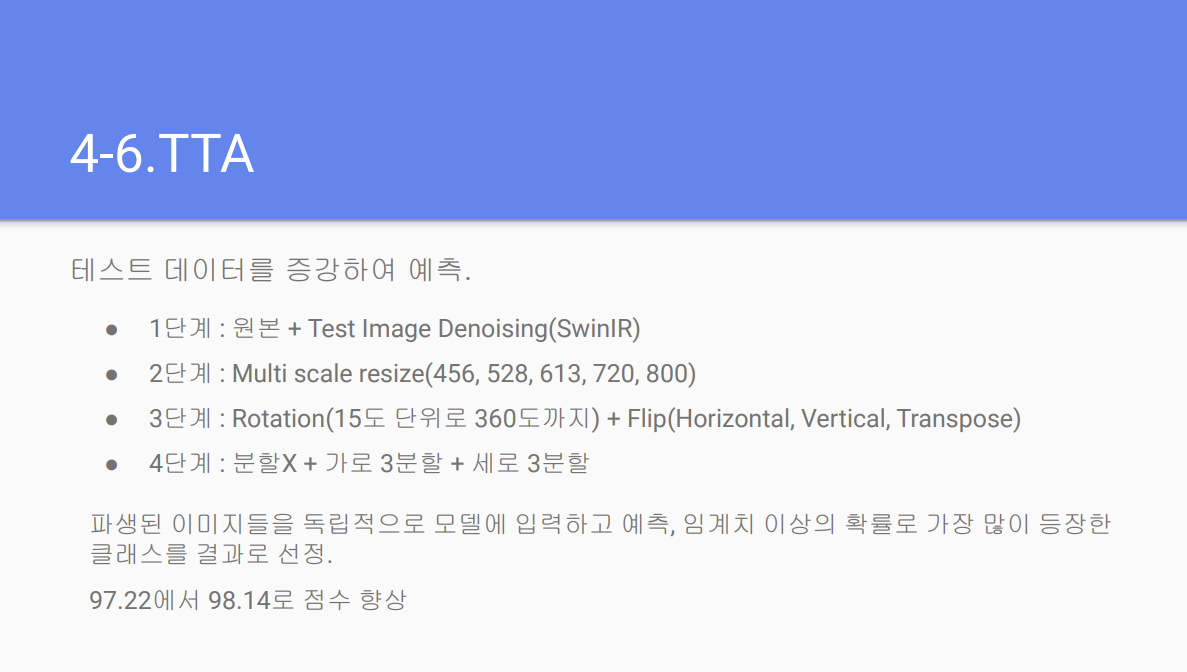
TTA 적용으로 98.14 까지 향상
나는 TTA도 한계가 있다고 생각했는데 이런 식으로 적용하면 효과를 볼 수 있다니. Crop적용안했으면 더 올라갔을 수도 있을 것 같음.
후기 총평
근본적인 문제를 해결하지 못했다니?? 이렇게 잘했는데??

5. 2위 팀, 6조의 실험에 대한 생각
Focal Loss
Focal Loss로 0.9417 --> 0.9794 로 상승했다고??
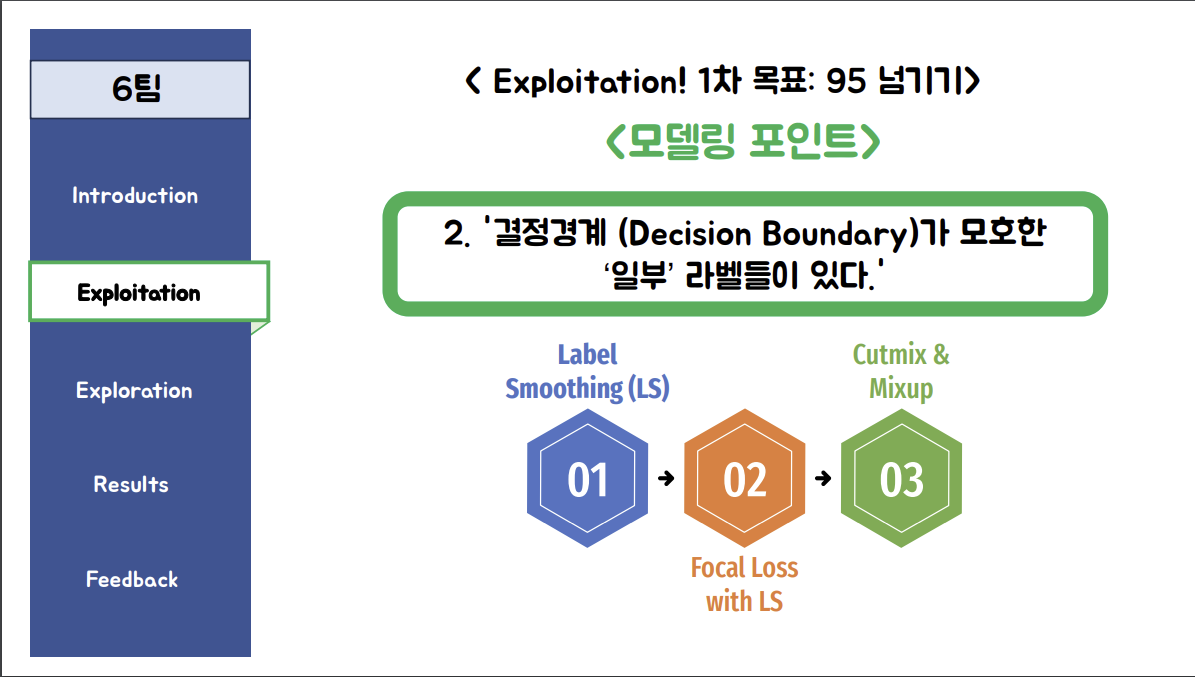

결정경계 극복을 위한 2차 분류기 시도
0.9794 --> 0.9851 ? 2차 분류기가 뭐지? De-augmentation해서 높였다는 이야기인가? 나는 6조 발표자에게 질문을 했다. focal loss로 0.9794 달성한 이후에 3,4,7,14 에 대해서만 모델을 만들어 98대까지 끌어올리신 것인지요?
6조 발표자의 답변:
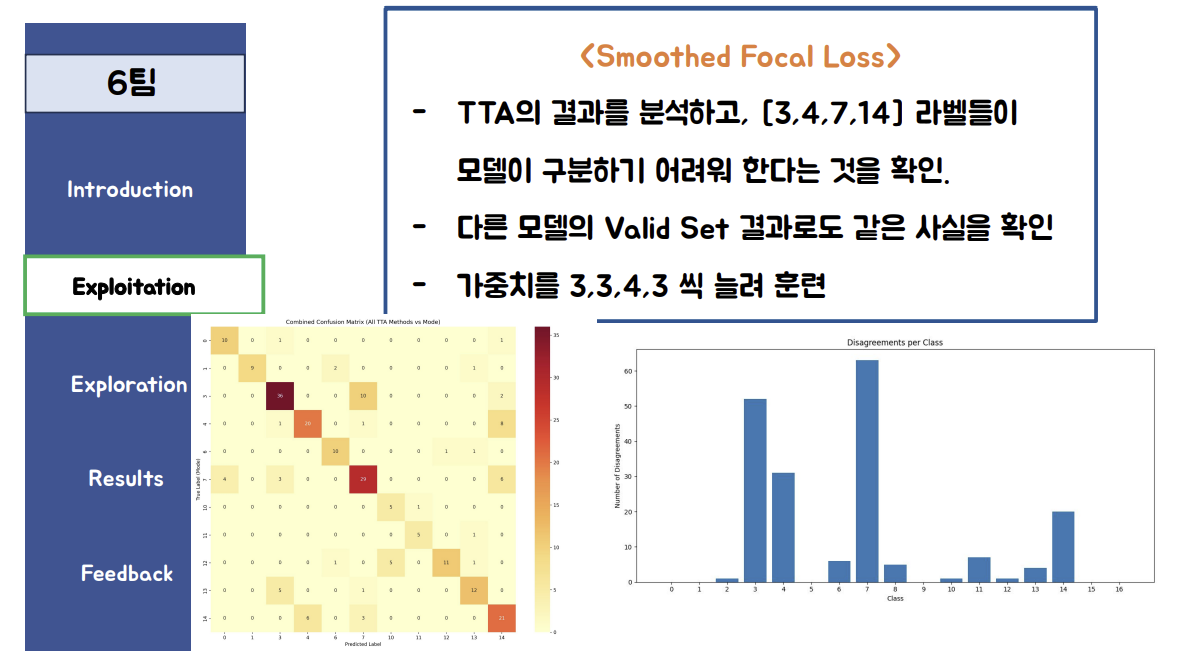
정확히는 레이블 스무딩을 적용한 포칼로스를 사용했고, 98을 달성한 것은 2차모델로 3,4,7,14로 예측한 것만 추론을 진행했습니다.
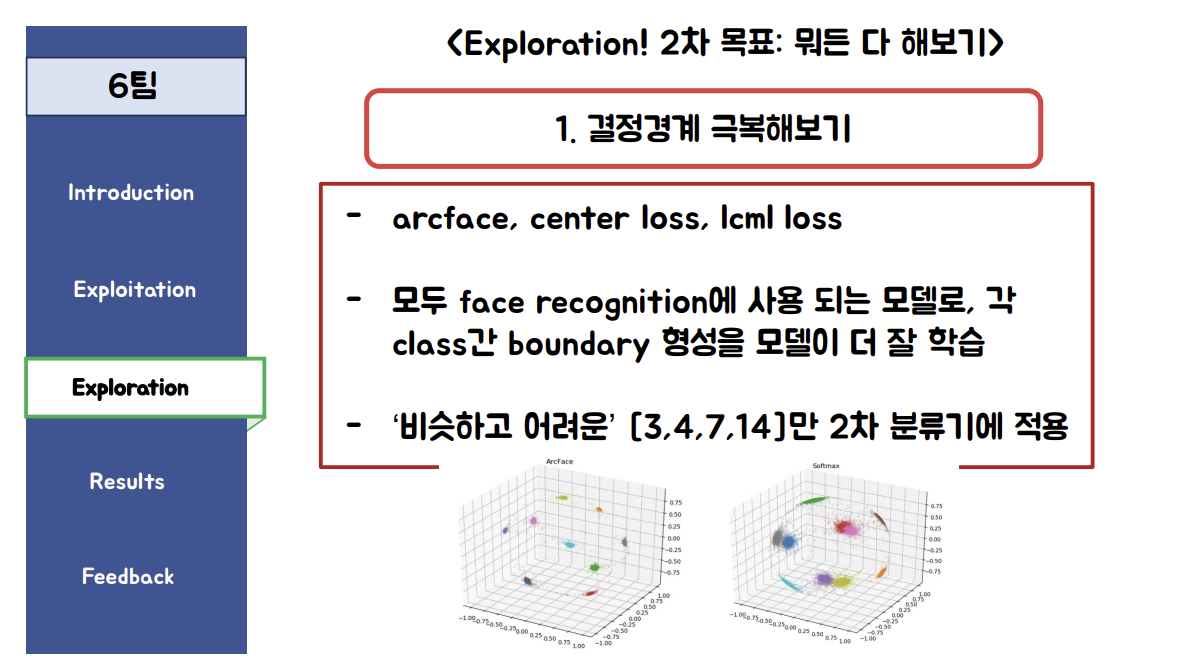
2차모델은 기존의 스무스 포칼 로스에 arcface라는 임베딩 로스를 더해서 학습한 모델입니다.사실 2차모델은 효과가 모델에 따라 갈려서 좋았는지는 모르겠네요 :)
아마 하이퍼파라미터를 베이지안으로 최적화하거나 sweep을 돌리면 더 좋은 결과가 나올 수도 있겠지만, 효과가 좋았는지는 사실 잘 모르겠습니다 ㅋㅋ 1차 모델에 따라 좀 갈리는 듯 합니다.
그니까 1차로는 smoothing label을 적용한 focal loss, 2차로는 target 3,4,7,14에 대해 arcface라는 임베딩 로스를 더해 학습한 모델을 적용했다는 것이다.


Focal Loss에 대해 알아봤다.
Focal Loss는 주로 객체 탐지와 같이 클래스 불균형이 심한 문제에서 사용되는 손실 함수입니다. 이 손실 함수는 Cross Entropy Loss의 일반화된 형태로, 간단한 예측에 대해서는 더 큰 손실을, 확실한 예측에 대해서는 더 작은 손실을 주어 학습의 효율성을 높입니다.
PyTorch에서의 Focal Loss
import torch
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
targets = targets.type(torch.float32)
at = self.alpha * targets + (1 - self.alpha) * (1 - targets)
pt = torch.exp(-BCE_loss)
F_loss = at * (1-pt)**self.gamma * BCE_loss
if self.reduction == 'mean':
return torch.mean(F_loss)
elif self.reduction == 'sum':
return torch.sum(F_loss)
else:
return F_lossArcFace 에 대해 알아봤다.
ArcFace는 얼굴 인식 작업에서 사용되는 고급 임베딩 기술 중 하나로, 특히 클래스 간의 각도 마진을 최적화하여 더 뚜렷하고 구별 가능한 특징을 학습하는 데 도움을 줍니다. 이 기술은 2018년에 Jiankang Deng 등에 의해 소개된 후 많은 얼굴 인식 시스템에서 중요한 컴포넌트로 사용되었습니다.
ArcFace의 원리
ArcFace는 Softmax loss에 각도 마진을 추가하여 클래스 간 분리를 개선하는 방식입니다. 기본 아이디어는 특징 공간에서 클래스 중심과 해당 클래스의 샘플 사이의 각도를 최적화하여 임베딩을 수행하는 것입니다. 이는 더 강한 구별력과 클래스 간 일관성을 유도합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ArcFaceLoss(nn.Module):
def __init__(self, s=64.0, m=0.5, easy_margin=False):
super(ArcFaceLoss, self).__init__()
self.s = s
self.m = m
self.easy_margin = easy_margin
self.cos_m = torch.cos(m)
self.sin_m = torch.sin(m)
self.th = torch.cos(torch.pi - m)
self.mm = torch.sin(torch.pi - m) * m
def forward(self, cosine, labels):
sine = torch.sqrt(1.0 - torch.pow(cosine, 2))
phi = cosine * self.cos_m - sine * self.sin_m
if self.easy_margin:
phi = torch.where(cosine > 0, phi, cosine)
else:
phi = torch.where(cosine > self.th, phi, cosine - self.mm)
one_hot = torch.zeros_like(cosine)
one_hot.scatter_(1, labels.view(-1, 1).long(), 1)
output = (one_hot * phi) + ((1.0 - one_hot) * cosine)
output *= self.s
loss = F.cross_entropy(output, labels)
return loss이 코드에서 ArcFaceLoss 클래스는 ArcFace 로스를 계산합니다. forward 함수는 입력으로 코사인 유사도와 레이블을 받아 손실을 계산하며, s와 m은 각각 스케일링 팩터와 마진입니다.
ArcFace는 특히 클래스가 많고 각 클래스 내의 예제 수가 적은 얼굴 인식과 같은 문제에 효과적입니다. 이를 통해 모델이 각 클래스를 더 잘 구별할 수 있도록 도와줍니다.
그니까 손실함수에 수학적으로 target간의 벡터 거리를 멀리만드는 기법이라고 생각하면 되나보다. 임베딩 공간에서 서로 다른 클래스의 샘플들이 더 분명하게 분리되도록 함으로써, 분류 과정에서의 식별력을 향상시키는 역할을 하는 것이다.
5. 그룹 스터디 진행 소감
우리 팀원들은 누가 조장이 되서 리드를 한 것은 아니었고 각자 눈치껏 분담하고 협업해서 다양한 실험을 시도해보았다. 아래처럼 모든 변수에 대해 테스트를 직접 시도해보았고 비전 모델 적용의 감각을 익혔다.
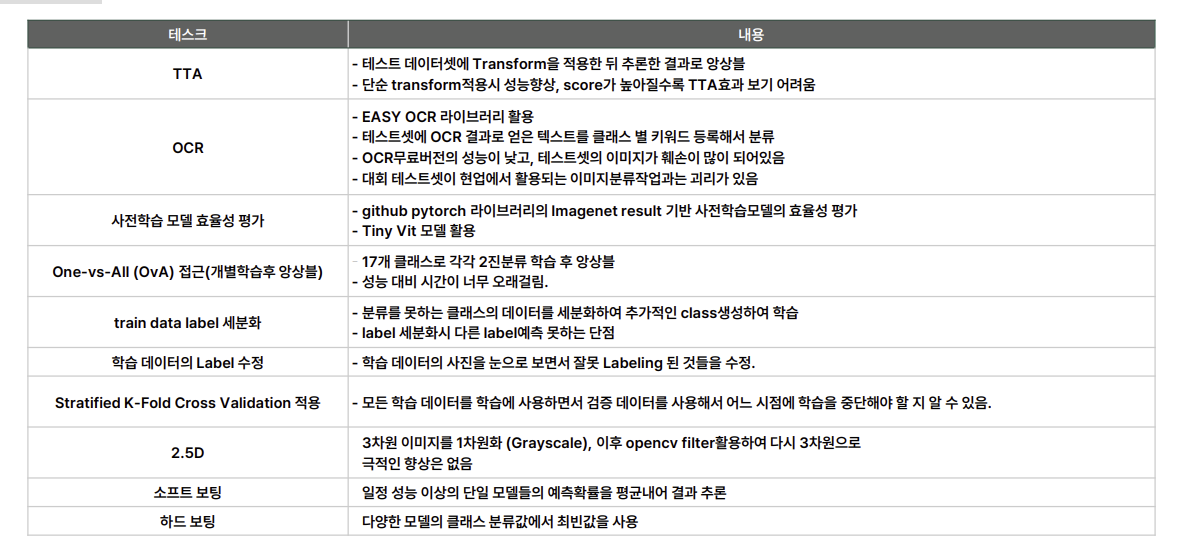
추가로 138회 제출이라는 횟수는 우리 조의 성실함을 보여준다고 생각한다. 무더운 여름 몸도 지치고 한 분은 감기로 몸이 안좋은데도 다들 최선을 다했다. 휴가철이기도 해서 이동도 잦고 싱숭생숭할텐데 5명 모두 실험에 대한 의지가 불타올랐다. 특히 나의 집착이 유효했던 것 같다. 프로젝트 하나 시작하면 정말 물어지게 붙잡는 더러운 성격이 대회 때마다 발동하는데 그 집념이 마지막까지 유효했다. 나처럼 OCR 시도한 조들을 많이 봤는데 유효한 모델로 만든 경우는 나밖에 없었다. OCR 노가다의 승리다.
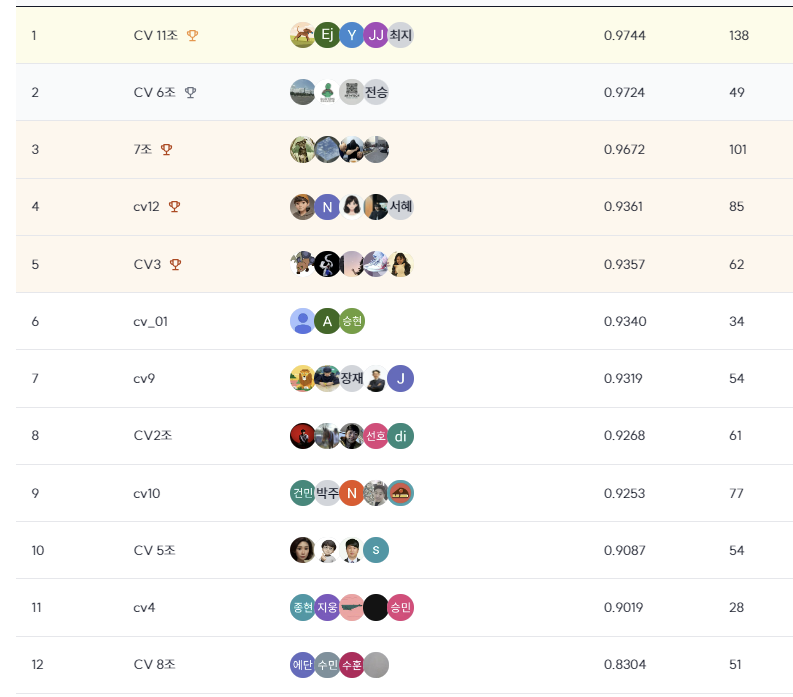
특히 마지막에 제출한 2개의 파일이 모두 0.9859 이고 아래 7개밖에 다르지 않았는데
ID target target
cd761b0adbcccb3f.jpg 3 7 diff
d2d64c506f6e8a40.jpg 7 3 diff
e3e998426289f278.jpg 4 7 diff
e6cda492548183c8.jpg 3 7 diff
eac82983b43782d7.jpg 3 7 diff
fc2a40463c5fbc62.jpg 7 3 diff
feae829823ba76c0.jpg 14 3 diff
대회가 끝나고 최종 private점수가 공개된 이후 final F1 score를 보니 마지막에 제출한 두 개의 파일이 0.9711과 0.9744이다. 2위가 0.9724 이니 겨우 이겼다고 볼 수 있다.
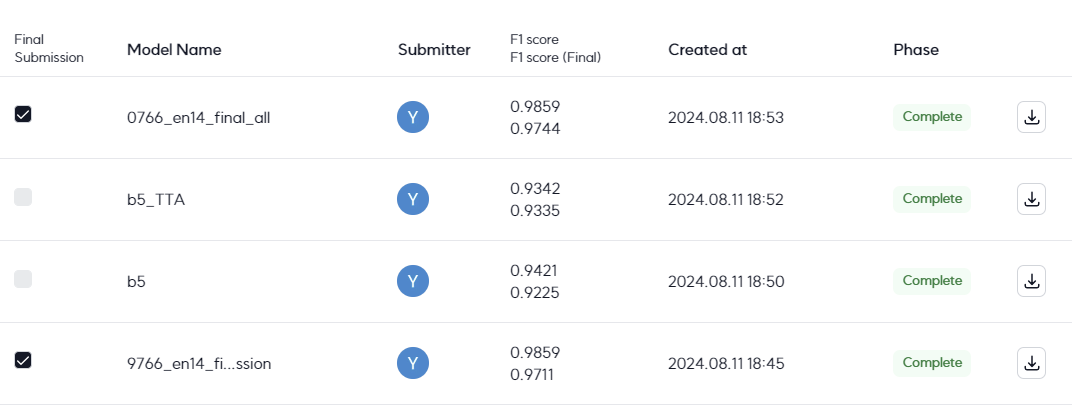
사실상 이 대회는 이 분야 학습을 위한 연습용 대회이지 일반화를 위한 대회는 아니라고 생각하면 된다. 우리 팀의 경우 앙상블도 심하게 적용했고, OCR 검출을 위해 padding, text 범위, keyword 설정 등을 계속 바꿨기 때문에 재현도 힘들다.
그래도 다양한 테스트를 모두 시도해보아서 많이 배웠다. 이번 대회를 통해 이미지 분류 및 vision분야에 대해 이해도를 높일 수 있어서 좋았다.
'Upstage AI 3기 > 프로젝트_개인회고' 카테고리의 다른 글
| [Scientific Knowledge Question Answering | 과학 지식 질의 응답 시스템 구축] IR 프로젝트 개인회고 (0) | 2024.10.27 |
|---|---|
| [Dialogue Summarization | 일상 대화 요약] NLP 프로젝트 개인회고 (7) | 2024.09.19 |
| [House Price Prediction | 아파트 실거래가 예측] ML프로젝트 개인회고 (0) | 2024.07.20 |
- Total
- Today
- Yesterday
- cnn
- LLM
- nlp
- 리스트
- PEFT
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- classification
- Lora
- git
- 손실함수
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- LIST
- English
- t5
- Hugging Face
- 코딩테스트
- RAG
- 티스토리챌린지
- Numpy
- Transformer
- recursion #재귀 #자료구조 # 알고리즘
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- Github
- speaking
- 파이썬
- 해시
- Python
- clustering
- Array
- 오블완
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |