
Table of Contents
[Scientific Knowledge Question Answering | 과학 지식 질의 응답 시스템 구축] IR 프로젝트 개인회고
꼬꼬마코더 2024. 10. 27. 17:131. 프로젝트 개요
A. 개요 : https://stages.ai/en/competitions/322
대화 히스토리를 기반으로 질문에 가장 알맞은 문서를 맞추는 것이 이번 대회 목표이다.
알맞은 문서는 1개 내지 2개일 수 있다고 강사님께서 언급하셨다.
topk를 1개를 제출하든 5개를 제출하든 상관은 없지만 MAP점수 매길 때 topk의 순위가 중요하다.

B. 환경: Upstage에서 제공하는 remote 서버연결
| GPU | CPU | Memory |
| RTX 3090 / 24 GB | 10 thread | 60G |
2. 프로젝트 팀 구성 및 역할
2-1. 매일 11시 어제 한 것, 유효한 부분, 내일 진행할 부분에 대해 공유, 모델학습실험기록지를 엑셀로 공유


2-2. 역할분담
진행속도가 빠른 사람이 실험결과 공유해주고, 후발주자가 성능 올릴 수 있거나 강의에 나온 팁들 및 신기술 서치해서 다양한 실험 진행
3.프로젝트 수행 절차 및 결과
3-1. 데이터 탐색:


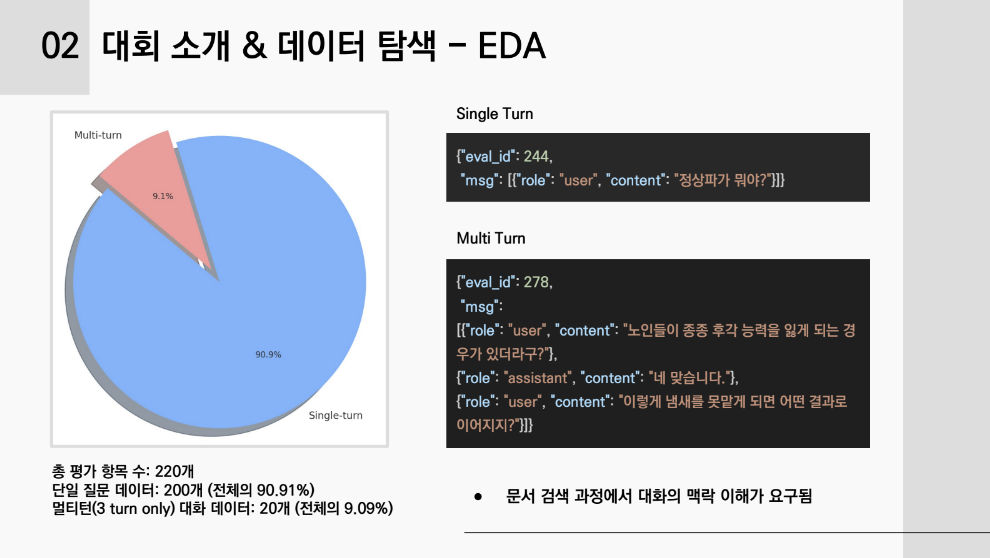

3-2. IR 파이프라인 구축:
일단 우리 팀의 최종 파이프라인은 2개이다.
1번: 무수한 실험으로 이뤄낸 모델
elasticsearch + 임베딩모델 snunlp/KLUE-SRoBERTa-Large-SNUExtended-klueNLI-klueSTS dimension 1024 + synonyms/user_dictionary + sparse/hybrid/dense retrieve + reranker + LLM
특징: hybrid retrieve / content에 keyword, summary, title추가 / query를 dialogue 전부 합친 combined_dialogue 를 사용

2번: 논문과 강의에 나온 기법을 모두 도입한 모델, LLM없이 0.9076달성
elasticsearch + 임베딩 모델 OpenAI embeddings_text-embedding-3-large dimenstion 3072 + synonyms/user_dictionary + sparse/colbert/dense retrieve + reranker
특징: 고차원 임베딩 사용/ colbert 적용 / content를 chunk로 분할하고 reranker 역시 chunk 문서를 적용

3-3. embedding: MAP 0.8까지는 고차원 임베딩이 효과가 있으나 그 이후 부터는 dense retrieve에 정답 문서가 없었음. sparse retrieve가 정답 문서를 잘 뽑아서 고차원 임베딩의 효과가 없었다.


3-4. chunking: naive와 semantic 방식이 있음. semanctic chunking 방식으로 문서를 chunk로 만들어 해당 chunk마다 question을 만들어 reranking을 학습시킨 효과가 좋았음.




3-5. standalone_query: 다양한 llm에서 standalone_query를 생성해봄. 그 중 Anthropic이 만들어준 query가 유용했으나, 실험상 standalone_query를 생성할 경우 단어가 줄어들면서 문맥을 조금 변형시키는 문제 때문인지 reranker, llm에서 combined_dialogue(대화문을 모두 연결)를 사용할 때 더 좋은 성능을 보였다.


3-6. Elasticsearch Indexing: jelinekMercer방식으로 lambda값을 0.7로 셋팅할 때 전체 코퍼스를 반영하여 특정 부분에 국한한 내용보다 일반적인 내용을 topk로 뽑

Elasticsearch Indexing: user_dictionary 및 synonyms 추가. 성능이 매우 좋은 reranker를 시도하기 이전에 시도한 synonyms작업. synonyms는 결국 query와 문서와의 간극을 줄이는 매우 중요한 역할이지만 사실상 현업에서는 관리가 어려워 이를 버리고 dense retrieve방식을 사용함. 효과는 매우 좋으나 관리에 어려움. 또한, mapping시 cosine보다 실험 결과가 좋은 l2_norm방식을 선택. cosine의 경우 형태가 유사한 문서를 뽑아주지만 맞는 내용의 문서를 뽑아주지 않는 결과를 보임.

Elasticsearch Indexing: content에 keyword, title, summary 정보를 추가하여 embedding시킴. query와의 간극을 줄이려는 시도. 또한 sparse를 should방식으로 retrieve하고 knn 방식과 합쳐서 최적의 조합 pool을 만듦. 최종 pool은 sparse+hybrid+dense 를 합쳐 pool을 다양화 함. 그 이유는 reranker가 탁월한 성능을 보여줬기 때문에 pool을 크게 하는 것이 점수 향상에 도움이 됐기 때문.

3-7. Colbert: 셋팅이 매우 어려움. reranker이전에는 효과가 좋았으나 reranker 도입 후 사실상 의미 없어짐.

3-8. Reranker: dongjin 리랭커의 효과가 매우 좋았음. 다른 팀의 경우 cohere 리랭커를 쓴 경우가 더 좋았다고 함. 리랭커가 뽑아준 topk 안에서 MAP0.9 가능했던 것 같음.

리랭커 모델을 훈련시켜보려고 했으나 negative pair를 만들 때 굉장히 세심한 데이터 생성 작업이 필요했음. 결국 실패했고, chunk방식으로 문장을 짧게 끊어서 content를 나누고 question을 만든다면 성공할 것 같음. 다음 부트캠프 기수에서 시도해주길 바랍니다.

4.프로젝트 회고
4-1. LLM prompt engineering의 중요성: output의 일관성을 보존할 수 있는 structured output을 활용하여 prompt를 만드는 것이 중요

4-2. LLM의 한계: llm호출할 때마다 달라지는 아웃풋, topk 10개를 던지면 나타나는 confabulation, 우리가 어디까지 신뢰하고 사용해야 할까?

4-3. 그러나 LLM의 필수적 역할: 문장마다 긴 호흡으로 판단할 수 있는 고도의 독해능력, 이를 llm없이 구현하기란 쉬운 일이 아님.

4-4. 프로젝트 결과: public 3위 --> private 1위, combined_dialogue의 효과 확인. 우리가 모델을 학습시킬 때 title, summary형식이 아닌 인간의 대화문 형식으로 학습하기 때문이 아닐까?
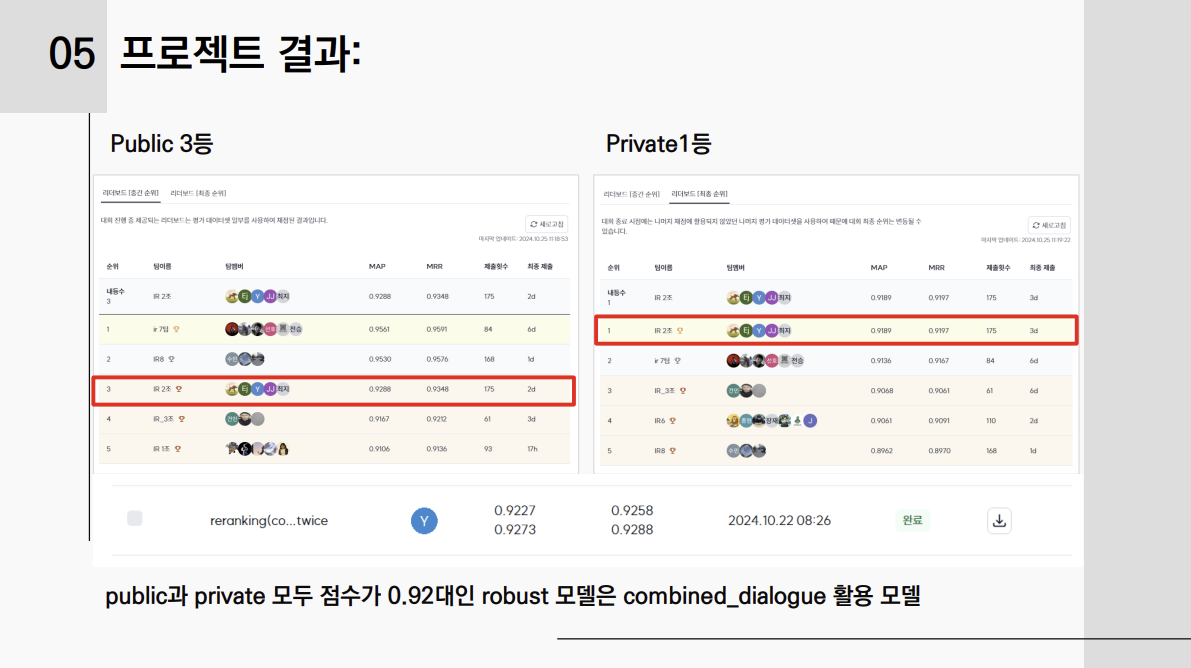
이번 Public에서 계속 92점에서 머물고 1,2위 팀의 95점을 넘지 못해서 사실상 더 이상 할 수 있는 시도가 없다고 생각되어 포기한 상태였다. 대회가 끝날때까지 다양한 실험결과를 제출했고 MAP점수 높은 자동점수로 Private에 제출되었는데 떡하니 1등을 하니 너무 신기할 따름이었다. 200개의 데이터가 수가 적었는지 public과 private의 간극이 큰 대회였다. 다행히 노력한 결과가 보상을 받는 것 같아서 기뻤고 무엇보다 치킨쿠폰을 받을 생각에 기쁘다. 마지막 프로젝트였는데 이렇게 1위로 예쁘게 마지막을 장식할 수 있어 기쁘다. 협업이 잘되는 우리 팀원들과 만날 수 있게 조를 짜준 박기준 매니저님께 감사의 말씀 드린다.
4-5. 다음 기수에게 전할 말:
저희 팀은 다양한 기법을 적용하였고, 그 중 reranker의 위력은 대단했습니다. reranker를 학습하려고 했지만 커다란 content보다는 세밀한 문장 단위로 trainingset을 만들어야 해서 negative pair 생성에 실패했습니다. 하지만 chunk 방식으로 content를 분할하는 방식이 효과가 좋았습니다.
아쉬운 점은 정확히 topk가 sparse에서 온건지 hybrid에서 온건지, dense에서 온건지 확인을 하지 못했다는 점입니다. tracking을 했다면 좋았을텐데 대회 점수에 집중하느라 tracking코드를 만들지 못했습니다.
다음 기수에서는 저희의 기존 git코드를 바탕으로 대회의 점수를 빠르게 올리고, 이 대회를 만든 강사님들의 코드를 활용(멘토님에게 문의)해서 IR의 깊은 training방식, 데이터셋을 어떤 방식으로 활용하여 어떻게 question을 만들지에 대한 부분, 그리고 어느 방식의 retrieve에서 topk가 온건지에 대해 초점을 두고 진행하셨으면 합니다.
'Upstage AI 3기 > 프로젝트_개인회고' 카테고리의 다른 글
| [Dialogue Summarization | 일상 대화 요약] NLP 프로젝트 개인회고 (7) | 2024.09.19 |
|---|---|
| [Document Type Classification | 문서 타입 분류] VISION 프로젝트 개인회고 (0) | 2024.08.12 |
| [House Price Prediction | 아파트 실거래가 예측] ML프로젝트 개인회고 (1) | 2024.07.20 |
- Total
- Today
- Yesterday
- PEFT
- classification
- Hugging Face
- Array
- LIST
- clustering
- git
- Lora
- cnn
- t5
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- LLM
- Transformer
- nlp
- Python
- 리스트
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- 파이썬
- speaking
- Numpy
- 오블완
- 해시
- 코딩테스트
- English
- RAG
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- 손실함수
- 티스토리챌린지
- Github
- recursion #재귀 #자료구조 # 알고리즘
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |