
Table of Contents
Abstract
We study empirical scaling laws for language model performance on the cross-entropy loss. 우리는 언어 모델 성능의 교차 엔트로피 손실에 대한 경험적 스케일링 법칙을 연구합니다.
The loss scales (비례한다) as a power-law (거듭제곱 법칙)with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. ( 단순히 7자리 값이 아니라 값의 범위가 매우 넓다는 의미, 모델 크기나 데이터셋 크기, 학습 자원이 10배, 100배, 1,000배, 10,000배까지 늘어나면서도 일정한 경향을 보인다는 것 )손실은 모델 크기, 데이터셋 크기, 학습에 사용된 계산 자원의 양에 따라 거듭제곱 법칙으로 축소되며, 이러한 경향은 7 자릿수 이상의 스케일에 걸쳐 나타납니다.
Other architectural details such as network width or depth have minimal effects within a wide range. 네트워크의 너비나 깊이와 같은 다른 아키텍처 세부 사항은 넓은 범위 내에서 성능에 미미한 영향을 미칩니다.
Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. 단순한 방정식이 모델/데이터셋 크기에 대한 과적합의 의존성과 모델 크기에 따른 학습 속도의 의존성을 설명합니다.
These relationships allow us to determine the optimal allocation of a fixed compute budget. 이러한 관계는 고정된 계산 예산의 최적 할당을 결정할 수 있게 해줍니다.
Larger models are significantly more sampleefficient, ( 적은 양의 데이터만으로도 효율적으로 학습하고 좋은 성능을 낼 수 있는 모델 ) such that optimally compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence. 큰 모델은 훨씬 더 효율적으로 학습하며, 따라서 최적으로 계산 효율적인 학습은 상대적으로 적은 양의 데이터로 매우 큰 모델을 학습시키고, 수렴 전에 학습을 멈추는 것이 포함됩니다.
실험방식
**"Scaling Laws for Neural Language Models"**에서 사용된 실험 방식은 문장의 **마지막 단어 부분을 잘라내고**, 모델이 주어진 문맥을 기반으로 **다음에 나올 단어를 얼마나 정확히 예측하는지** 평가하는 방식입니다.
구체적으로는, 모델에 주어진 문장(입력)에서 **마지막 단어를 예측하도록** 훈련된 후, 모델이 예측한 단어와 실제 단어(타겟)를 비교하여 **교차 엔트로피 손실(cross-entropy loss)**을 계산했습니다. 이 과정에서 모델이 텍스트 흐름을 얼마나 잘 이해하고 예측하는지를 평가했습니다.
특히, **Non-embedding 파라미터**만 사용해 테스트를 진행했다는 것은 **임베딩 레이어**에서 텍스트를 벡터로 변환하는 과정을 제외하고, **모델의 나머지 부분**(트랜스포머 블록 등)을 평가했다는 뜻입니다.
즉, 이 논문에서는 모델이 **입력된 텍스트로부터 임베딩을 학습하는 과정**을 고려하지 않고, **파라미터 수와 데이터 크기에 따른 모델의 추론 성능**(다음 단어 예측 능력)을 중점적으로 분석한 것입니다.
따라서 **임베딩 이후의 모델 구조만으로도 문장 생성 능력을 평가**했다는 의미가 됩니다.
파라미터 개수와 test loss 관계 및 모델훈련의 일관성 확인

- 왼쪽 그래프: 모델 크기가 커질수록 다른 데이터 분포에서의 일반화 성능이 점진적으로 개선되며, 훈련 데이터(WebText2)와 비교할 때 성능 차이는 작고 천천히 증가합니다.
- 오른쪽 그래프: 일반화 성능은 훈련 데이터에서의 성능에만 의존하며, 훈련의 어느 단계에서든 비슷한 경향을 보입니다. 이 그래프는 수렴된 모델들의 성능(점)과 훈련 중인 하나의 큰 모델의 성능(점선)을 비교하고 있습니다.
-
오른쪽 그래프는 모델의 일반화 성능이 훈련 과정에서 얼마나 일관되게 유지되는지를 보여줍니다. 여기서 중요한 점은, 훈련 분포에서의 성능과 다른 데이터 분포에서의 성능 간에 일정한 관계가 있다는 것입니다.
그래프에서 점들은 수렴된 모델들(convergence)의 성능을 나타내고, 점선은 훈련 중인 큰 모델의 성능을 나타냅니다. 설명에 따르면, 일반화 성능은 모델이 훈련되는 단계에 관계없이 훈련 데이터에서의 성능에 의해 결정되며, 훈련 중이든 수렴된 후이든 유사한 패턴을 보입니다.
데이터 크기와 모델 크기가 모델 성능과 과적합에 미치는 영향

- 왼쪽 그래프: 데이터 크기가 클수록 모델 크기를 증가시킬수록 성능이 지속적으로 개선
- 오른쪽 그래프: X축: 데이터 크기 대비 모델 크기의 비율. Y축: 과적합 정도. 과적합은 모델 크기가 데이터 크기보다 클 때 증가.
- 큰 모델은 항상 작은 모델보다 성능이 더 좋다고 예상되지만, **데이터 크기(D)**가 한정되어 있으면 아무리 큰 모델이라도 최적 성능(최소 손실)에 도달하지 못한다는 것을 설명합니다.
- 과적합은 데이터 크기(D)가 커질수록 줄어든다는 가정을 제시하며, 데이터가 많아질수록 모델이 과적합하는 경향이 적어진다고 합니다.
모델 크기(파라미터 수)와 계산 자원 및 훈련 단계가 모델 성능(테스트 손실)에 미치는 영향

- 왼쪽 그래프: 계산 자원이 고정된 상태에서 모델 크기가 커질수록 성능이 향상되지만, 일정한 크기 이후에는 성능 향상이 한계에 도달합니다.
- 오른쪽 그래프: 훈련 단계가 많아질수록 성능이 좋아지지만, 일정 수준에 도달하면 성능 향상이 둔화됩니다.
모델 크기(파라미터 수)와 계산 자원 및 훈련 단계가 모델 성능(테스트 손실)에 미치는 영향

Figure 12
- 왼쪽 그래프: 고정된 계산 자원 하에서, 최적 모델 크기(N/Nₑₓₑffₑₗient) 근처에서는 약간 큰 모델이나 작은 모델도 성능에 큰 차이가 없이 훈련될 수 있음을 보여줍니다.
- 오른쪽 그래프: 작은 모델은 더 많은 훈련 단계가 필요하지만, 큰 모델은 상대적으로 더 적은 훈련 단계로도 효율적으로 훈련될 수 있음을 보여줍니다.
Figure 13
- 계산 자원이 달라질 때의 성능을 그래프로 보여주며, 계산 자원이 충분하지 않으면 성능이 저하될 수 있음을 보여줍니다.
계산 자원(PF-days)이 모델 크기와 최적화 단계 수(steps)에 어떤 영향을 미치는지

- 왼쪽 그래프: 계산 자원이 증가할수록 모델 크기도 증가하며, 특히 10배 더 많은 계산 자원을 사용할 때 모델 크기는 5배 증가합니다.
- 오른쪽 그래프: **조정된 배치(batch-adjusted)**에서 훈련 단계 수는 천천히 증가하며, 대부분의 계산 자원 증가가 배치 크기 확장에 사용됩니다. fixed batch로 실험을 하면, 계산 자원이 많아질수록 훈련에 필요한 스텝(step) 수가 많아지는 경향이 있습니다. 즉, 계산 자원이 더 많아지면 전체 데이터셋을 처리하는 능력이 커지고 배치 수가 늘어나게 됩니다. 그 결과 훈련 단계가 더 많아집니다.
- 따라서, 계산 자원을 늘리면 모델 크기는 빠르게 증가하지만, 최적화 단계 수는 상대적으로 천천히 증가한다는 것을 보여줍니다.
계산 자원(Compute)과 테스트 손실(Test Loss) 간의 관계
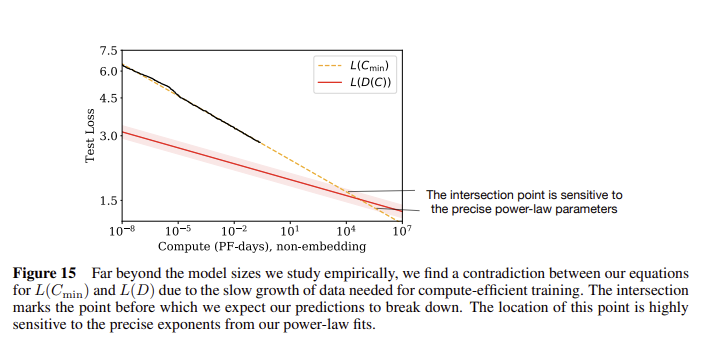
- 교차점: 이 지점은 계산 자원과 데이터 크기 간의 상관 관계가 예상과 다르게 동작하는 지점입니다.
- 교차점의 민감성: 거듭제곱 법칙의 매개변수에 매우 민감하게 반응하며, 이 지점 이후에는 더 이상 예측이 잘 맞지 않을 수 있습니다.
- 그래프의 결론은 계산 자원이 많을 때 학습의 효율이 감소하는 구간을 보여줍니다. 10^4에서 10^5 PF-days 사이에서 효과적인 손실 감소가 둔화되는 현상을 나타냅니다. 이는 이 구간에서 모델 크기 또는 데이터 크기 증가만으로는 더 이상 성능 향상을 크게 기대하기 어려울 수 있다는 의미입니다. 계산 자원이 충분해지면, 효율적인 데이터 처리 및 모델 설계가 중요해진다는 점을 시사합니다.
논문리뷰요약
- 이 논문은 non-embedding 파라미터만을 사용하여 10^9 (십억) 파라미터 수준까지 실험을 진행함.
- Bert Large가 3.4억, T5 Large가 11억, GPT-3가 1750억.
- 이 논문은 **모델 크기와 성능 간의 관계를 체계적으로 정의**함으로써, 이후 더 큰 언어 모델(GPT-3, PaLM 등)의 개발에 중요한 이론적 토대를 제공했음.
- 이 논문의 핵심은 **대형 언어 모델**의 성능이 **모델 크기**, **데이터 크기**, 그리고 **계산 자원**과의 관계에서 어떻게 스케일링되는지를 설명하는 **경험적 스케일링 법칙**을 제안하는 것. 논문은 **모델이 클수록 더 적은 데이터로도 더 나은 성능을 발휘**할 수 있음을 보여주며, **과적합과 일반화 성능**에 대한 분석을 통해 최적의 모델 크기와 자원 배분 방법을 논의함.
- 이 논문에서는 non-embedding 파라미터만을 사용해 모델 성능을 평가했기 때문에, embedding 파라미터까지 포함하여 더 복잡한 추론 작업을 처리하려면 더 큰 파라미터의 모델이 필요하게 됨.
- 따라서, 추론 작업이 복잡해질수록 모델 크기(파라미터 수)를 늘려 복잡한 패턴을 학습하는 것이 중요하다는 뜻.
'DeepLearning > NLP' 카테고리의 다른 글
| LoRA(Low-Rank Adaptation)와 프롬프트 튜닝(Prompt Tuning) 차이 (0) | 2024.09.19 |
|---|---|
| prompt tuning (0) | 2024.09.19 |
| [LLM] LLM 모델이 LM 모델과 달라진 점 (0) | 2024.09.19 |
| [LLM] LM에서 LLM으로 발전하는 과정에서의 주요 변화 (0) | 2024.09.19 |
| [논문 리뷰] Pre-train, Prompt, and Predict: A Systematic Survey ofPrompting Methods in Natural Language Processing (0) | 2024.09.19 |
- Total
- Today
- Yesterday
- RAG
- 리스트
- Transformer
- clustering
- LLM
- 손실함수
- 티스토리챌린지
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- Lora
- English
- 해시
- Array
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- Hugging Face
- LIST
- 코딩테스트
- nlp
- recursion #재귀 #자료구조 # 알고리즘
- classification
- t5
- 파이썬
- PEFT
- 오블완
- Github
- Numpy
- git
- speaking
- cnn
- Python
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |