

Table of Contents
728x90
import pandas as pd
셀트리온_df=pd.read_excel(r'C:\Users\user\Downloads\셀트리온_20200501-20210501.xlsx')
셀트리온_df['일자'] = 셀트리온_df['일자'].astype('str')# 한 날짜로 데이터 합치기
pv_0 = pd.pivot_table(셀트리온_df, values='제목', index='일자', aggfunc='sum')pv_0.reset_index(inplace=True)pv_0.columns.valuespv_0from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from datetime import datetime, timedelta
#최종 데이터 프레임
tfidf2021제목_셀트리온 = pd.DataFrame()
for idx, row in pv_0.iterrows():
# 입력 텍스트 데이터
date = row['일자']
data = row['제목']
# 사용자 정의 스톱워드 리스트
#custom_stopwords = ['오늘', '포토', '종합', '서울', '다음', '영상']
# TF-IDF 벡터화 객체 생성 TfidfVectorizer를 사용하여 스톱워드 지정
tfidf_vectorizer = TfidfVectorizer()
#tfidf_vectorizer = TfidfVectorizer(stop_words=data)
# TF-IDF 가중치 계산
tfidf_matrix = tfidf_vectorizer.fit_transform([data])
# 결과 출력
feature_names = tfidf_vectorizer.get_feature_names_out()
tfidf_values = tfidf_matrix.toarray()
feature_names_df = pd.DataFrame(feature_names, columns=['feature_'+date])
tfidf_values_df = pd.DataFrame(tfidf_values.T, columns=['tfidf_'+date])
tfidf_daily_temp = pd.concat([feature_names_df, tfidf_values_df], axis=1)
tfidf_daily_temp = tfidf_daily_temp[tfidf_daily_temp.iloc[:,1]>0.00000000000001].sort_values(by='tfidf_'+date, ascending=False)
tfidf2021제목_셀트리온 = pd.concat([tfidf2021제목_셀트리온, tfidf_daily_temp.reset_index(drop=True)], axis=1, ignore_index=False)
tfidf2021제목_셀트리온.to_csv('tfidf2021제목_셀트리온.csv', index=False, encoding='utf-8-sig')tfidf2021제목_셀트리온from datetime import datetime, timedelta
row_data = []
start_date = datetime(2020, 5, 1)
end_date = datetime(2021, 5, 1)
current_date = start_date
for i in range(1,len(tfidf2021제목_셀트리온.columns)+1,1):
#print(tfidf_daily_제목_2019.iloc[:50,i-1:i+1])
date = current_date.strftime('%Y%m%d')
print(date)
feature =tfidf2021제목_셀트리온[f'feature_'+date].values
#tfidf =tfidf2021제목_셀트리온[f'tfidf_'+date].values
pair = []
for j in range(50):
#pair.append([feature[j], tfidf[j]])
pair.append(feature[j])
row_data.append({
'일자': date,
'feature': pair
})
i=i*2
if current_date == end_date:
break
current_date += timedelta(days=1)
daily제목feature_2021_셀트리온 = pd.DataFrame(row_data)df=daily제목feature_2021_셀트리온df['일자'] = pd.to_datetime(df['일자'], format='%Y%m%d')
# 월 단위로 그룹화하여 feature 합산
df['month'] = df['일자'].dt.to_period('M')
pivot_df = df.groupby('month')['feature'].sum().reset_index()
# 결과 확인
print(pivot_df)
from collections import Counter
# 초기 빈 데이터프레임 생성
final_df = pd.DataFrame()
# 기간 설정
start_date = pd.Period('2020-05', freq='M')
end_date = pd.Period('2021-04', freq='M')
# 각 월별로 루프를 돌며 데이터 처리
for date in pd.period_range(start=start_date, end=end_date, freq='M'):
# 연월 단위로 데이터 필터링
feature2005 = pivot_df[pivot_df['month'] == date]
# 'feature' 컬럼의 리스트를 펼쳐서(flatten) 모든 값을 하나의 리스트로 만듭니다.
all_features = [item for sublist in feature2005['feature'] for item in sublist]
# 각 값의 등장 횟수를 카운트합니다.
feature_counts = Counter(all_features)
# Counter 객체를 딕셔너리로 변환
counts_dict = dict(feature_counts)
# 딕셔너리를 데이터프레임으로 변환
feature_counts_df = pd.DataFrame(list(counts_dict.items()), columns=['feature_'+str(date), 'count_'+str(date)])
# 데이터프레임 내림차순
feature_counts_df.sort_values(by='count_'+str(date), ascending=False, inplace=True)
# 결과 데이터프레임 병합
if final_df.empty:
final_df = feature_counts_df
else:
#final_df = pd.merge(final_df, feature_counts_df, on='feature_'+str(date), how='outer')
final_df = pd.concat([final_df, feature_counts_df.reset_index(drop=True)], axis=1, ignore_index=False)
final_df.to_csv('셀트리온_워드클라우드.csv', index=False, encoding='utf-8-sig')final_df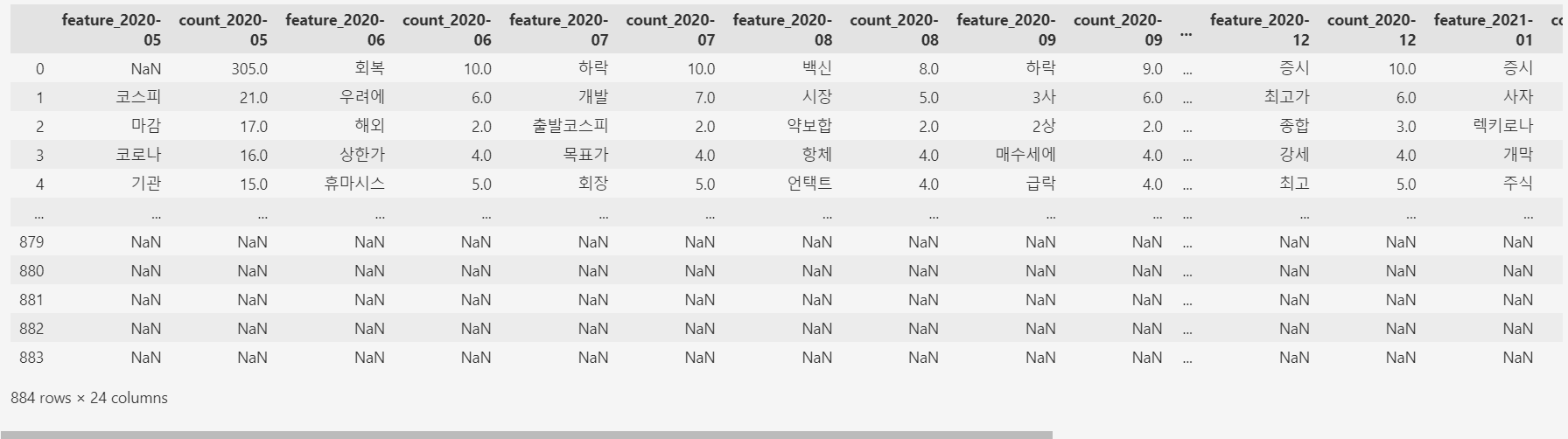
'Upstage AI 3기' 카테고리의 다른 글
| [패스트캠퍼스 Upstage AI 부트캠프] 과정 중간 회고 학습 블로그 (1) | 2024.07.14 |
|---|---|
| [패스트캠퍼스] Upstage AI Lab 3기 학습 블로그_코딩 테스트:자료구조 및 알고리즘 개론 (재귀 recursion) (0) | 2024.05.17 |
| [학습 블로그] 프로젝트 수행을 위한 이론 : Python EDA (0) | 2024.05.01 |
| [학습블로그] Git commit 메시지 (0) | 2024.04.23 |
| [학습블로그]Git 협업 프로젝트 수행 (0) | 2024.04.23 |
250x250
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- clustering
- 오블완
- Github
- #패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #무료교육 #국비지원 #국비지원취업 #데이터분석취업 등
- Array
- #패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- 리스트
- 티스토리챌린지
- 파이썬
- 손실함수
- LIST
- English
- git
- Hugging Face
- speaking
- LLM
- PEFT
- #패스트캠퍼스 #패스트캠퍼스ai부트캠프 #업스테이지패스트캠퍼스 #upstageailab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트캠프
- t5
- 코딩테스트
- cnn
- Python
- Numpy
- 해시
- nlp
- classification
- RAG
- Lora
- Transformer
- recursion #재귀 #자료구조 # 알고리즘
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
글 보관함